VLK 用合成場景訓練人形機器人
VLK 證明可用重建室內場景合成視覺、語言與運動監督,訓練人形機器人完成導航與單物件搬運。

VLK 證明可用重建室內場景合成視覺、語言與運動監督,訓練人形機器人完成導航與單物件搬運。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:48,000 組配對軌跡
- 突破點:重建場景再合成軌跡
這篇論文的重點很直接:如果人形機器人缺的是「看得見、聽得懂、做得出」三者對齊的資料,那就先把這種資料合成出來。VLK 不是只補一個動作標籤,而是把視覺、語言、運動軌跡一起做成可訓練的監督訊號,拿來訓練具身人形機器人的導航與操作能力。
對台灣做機器人或 embodied AI 的團隊來說,這種做法很有現實感。真正卡住的常常不是模型結構,而是資料。真人遙操作貴、慢,而且很難把第一人稱影像、任務指令、全身運動軌跡在同一情境下完整收齊。VLK 的主張是:既然難收,就先用重建場景把這三種監督一起造出來。
它要解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這篇論文鎖定的是 perception-based humanoid loco-manipulation,也就是人形機器人一邊移動、一邊和物件互動,還得依賴第一人稱觀測與語言指令來完成任務。這比單純走路更難,也比單純抓取更難,因為政策不只要知道怎麼動,還要知道看到什麼、指令在說什麼,才能把感知和全身控制接起來。

作者指出的核心缺口,是目前沒有資料來源能在大規模下提供同步的 egocentric 影像、語言命令與機器人可用的 kinematic trajectories。少了其中一項,模型就只能靠間接推斷補洞。這對人形系統很傷,因為它學到的不是完整任務,而是破碎片段。
這也是為什麼這篇不是單純在談 policy architecture。它的立場比較像是:資料管線本身就是關鍵技術。若沒有對齊好的多模態監督,再強的模型也很難學會真實世界裡那種「先走到位,再動手做」的長流程任務。
VLK 到底怎麼做
VLK 是 vision-language-kinematics 的縮寫,方法本身就是圍繞這三種訊號設計。第一步是用 3D Gaussian Splatting 重建室內環境,得到具尺度的場景表示。這個重建結果不是拿來展示,而是當作 privileged information,讓系統可以在知道空間結構的前提下,生成導航與物件互動的軌跡。
接著,系統才在這些軌跡之後渲染對應的第一人稱觀測。這個順序很重要。它不是先蒐集影像,再回頭猜動作;而是先用場景知識做出可行的動作規劃,再產生和軌跡對齊的 egocentric 視角。這樣做出來的資料,影像、指令與運動軌跡是從一開始就綁在一起的。
論文摘要提到,這條管線可以在沒有人工介入的情況下產生 48,000 組配對軌跡。這些資料再拿去訓練 VLK policy,讓模型預測短視野的全身 kinematic trajectories。最後由 whole-body tracker 把這些預測轉成實際機器人動作。
這種拆法對工程師來說不陌生。模型負責產生結構化的運動目標,控制器負責把目標落地成動作。好處是學習目標比較清楚,控制層也不用被迫直接吞下所有感知與規劃問題。對人形機器人來說,這種分工通常比端到端硬接到底更容易調。
論文證明了什麼
摘要裡唯一明確公開的數字,是 48,000 組配對軌跡。除此之外,摘要沒有公開完整 benchmark 細節,所以沒有辦法從這份資料直接讀出更細的百分比提升或和哪些 baseline 比較。
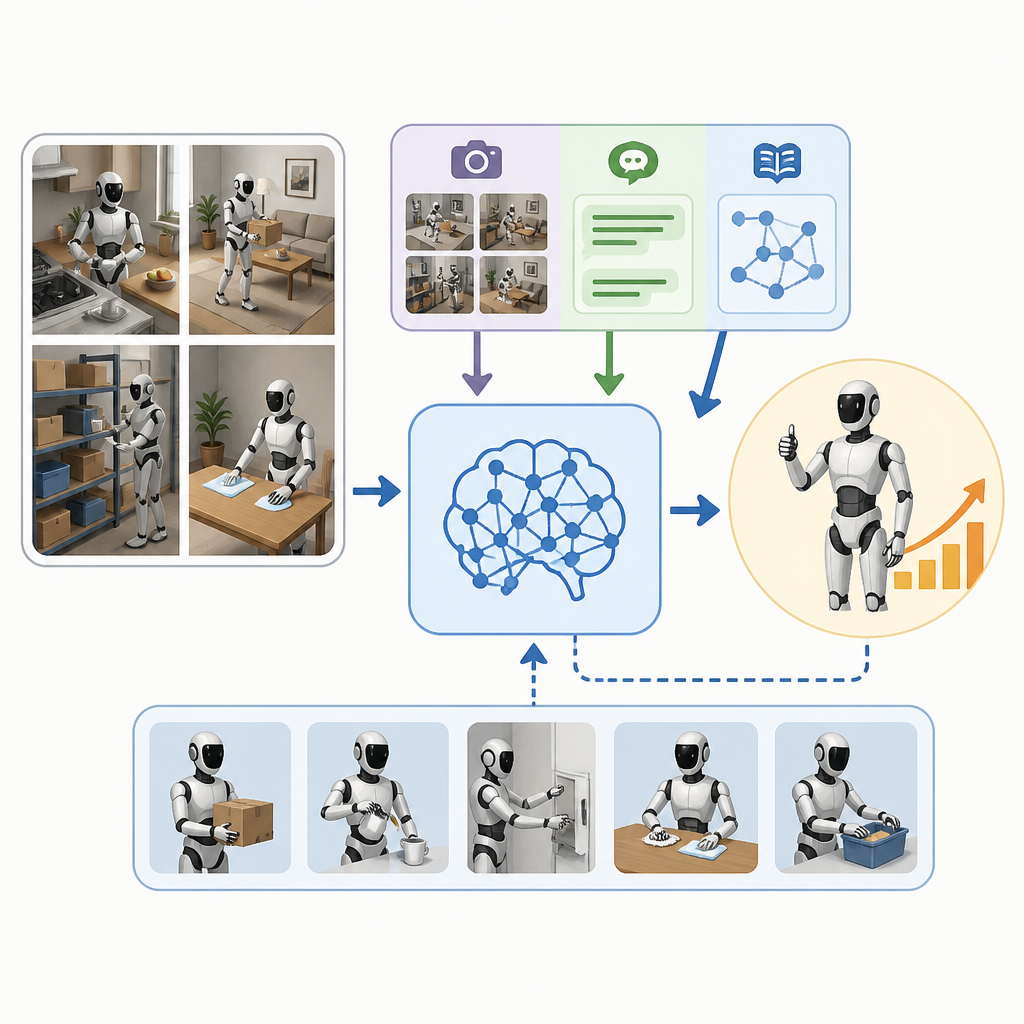
但作者至少證明了一件事:這種合成監督可以拿來訓練真實人形機器人。論文在物理平台 Unitree G1 上評估,任務是導航與單物件搬運。也就是說,合成自重建場景的互動資料,不只是能讓模型在資料集上看起來合理,還能轉到實機上做這兩類任務。
這裡要注意,論文的主張其實很節制。它沒有說自己解決了所有人形操作,也沒有在摘要裡宣稱可泛化到所有開放世界任務。它證明的是一個更具體的命題:在重建室內場景中合成出來的 vision-language-kinematics 監督,足以支撐 perception-based humanoid loco-manipulation 的實機訓練。
因為摘要沒有 benchmark 數字,所以更合理的讀法是:這篇展示了可行性,不是完整性能報告。你可以知道它有實機測試、知道它有 48,000 組軌跡,也知道任務範圍是導航與單物件搬運,但你還不知道它相對基線強多少、跑了多少次、在多少種環境裡穩定。
對開發者有什麼實際影響
如果你在做機器人學習,這篇最有價值的訊號是:高品質的多模態資料,可能不一定要靠真人一筆一筆收。只要能把場景重建起來,就有機會從幾何資訊合成出對齊好的訓練對,讓資料規模比純遙操作大很多。
這也提供了一條比較具體的資料生產流程:先重建室內場景,再用場景幾何生成軌跡,接著渲染對應的第一人稱畫面,最後把這些配對資料拿去訓練 policy。對做 embodied AI 的團隊來說,這比單靠人工示範更像一套可擴充的工程管線。
但限制也很明顯。摘要只談室內環境,任務只明講導航與單物件搬運,所以它能覆蓋的場景範圍並不廣。方法還依賴重建後的場景與 privileged scene information,代表你得先有可用的重建結果,合成資料才有意義。
另一個問題是擴展性。摘要沒有說這套方法在雜亂環境、長時序任務、或更複雜的物件互動上表現如何。對實務團隊來說,這些才是決定能不能落地的關鍵。也就是說,VLK 很像一個可行的資料生成策略,但還不是能直接套用到所有人形任務的通用解法。
你在完整論文裡應該找什麼
如果要評估這方法能不能進你的 stack,最重要的缺口是摘要沒講的部分:基線比較、失敗案例、以及對場景重建品質有多敏感。這些資訊會決定它是一次性的技巧,還是可以重複使用的訓練策略。
也值得看清楚短視野 kinematic trajectory 的輸出格式、whole-body tracker 的設計,以及 policy 是否高度依賴特定的重建流程。摘要已經把高層概念講清楚,但真正的工程價值,通常藏在這些實作細節裡。
總結來說,VLK 證明的不是「人形機器人突然變強了」,而是另一件更務實的事:如果你能把室內場景重建得夠好,就有機會合成出人形 loco-manipulation 需要的對齊資料。對想把機器人訓練從稀缺真人示範,推向可擴充合成監督的人來說,這是一個很值得注意的方向。