AI Data Ops 與 MLOps 的分工
Digital Divide Data 釐清 AI Data Operations 與 MLOps 的分工:前者管資料,後者管模型上線與維運。

AI Data Operations 管理模型學習的資料,MLOps 負責模型在生產環境中的運行。
Digital Divide Data 在 2026 年 6 月 29 日的一篇文章中,把這兩個常被混在一起的職能拆開來看。作者 udit khanna 指出,很多團隊只做了 MLOps,卻沒把資料層的責任講清楚。
| 項目 | 數值 |
|---|---|
| Publication date | June 29, 2026 |
| AI Data Operations scope | Collection, annotation, curation, human feedback, evaluation sets |
| MLOps scope | Training, deployment, monitoring, retraining |
| Main failure mode | Upstream data drift or label drift |
發生了什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這篇文章先把邊界畫得很清楚:Digital Divide Data 所說的 AI Data Operations,管的是模型學習前與評測時用到的資料資產;MLOps 則管訓練後的部署、監控與重訓。兩者都重要,但責任不同。
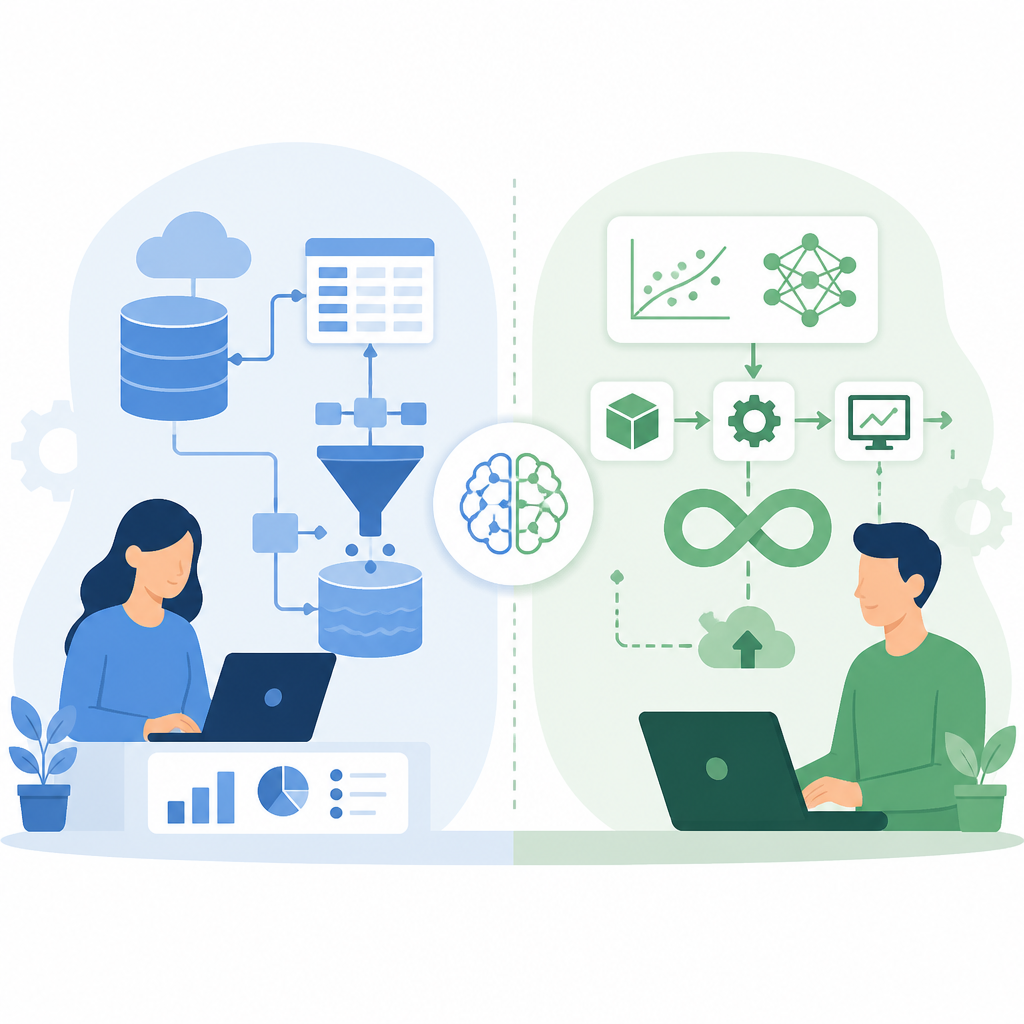
作者把 AI Data Operations 定義成資料收集、標註、整理、人工回饋與評估集管理。這些工作看起來像前置作業,實際上卻直接決定模型看到的是什麼、學到的是什麼,以及測試時會被怎麼評分。
文章也提醒,很多小型 AI 專案常由同一組人把資料和模型一起處理,表面上省事,實際上會把問題來源藏起來。模型在 production 出現異常時,真正的原因往往不是程式碼,而是標籤定義變了、資料整理流程改了,或某個欄位在管線中被漏掉。
- AI Data Operations 關注資料品質、標註一致性與評估集可用性。
- MLOps 關注可重現性、可追溯性與線上行為。
- 前者更像資料層治理,後者更像模型生命週期管理。
- 作者也把 AI Data Operations 放在 data-centric AI 的脈絡,而不是傳統 DataOps。
這種切法的重點,是把「資料能不能用」和「模型能不能跑」分成兩個問題。前者決定模型學到什麼,後者決定模型能不能穩定交付。
為什麼重要
對開發者來說,這篇文章最實際的提醒是:離線測試過關,不代表線上就會正常。只要資料過時、標註含糊,或資料分布悄悄漂移,模型就可能在真實場景裡失準。
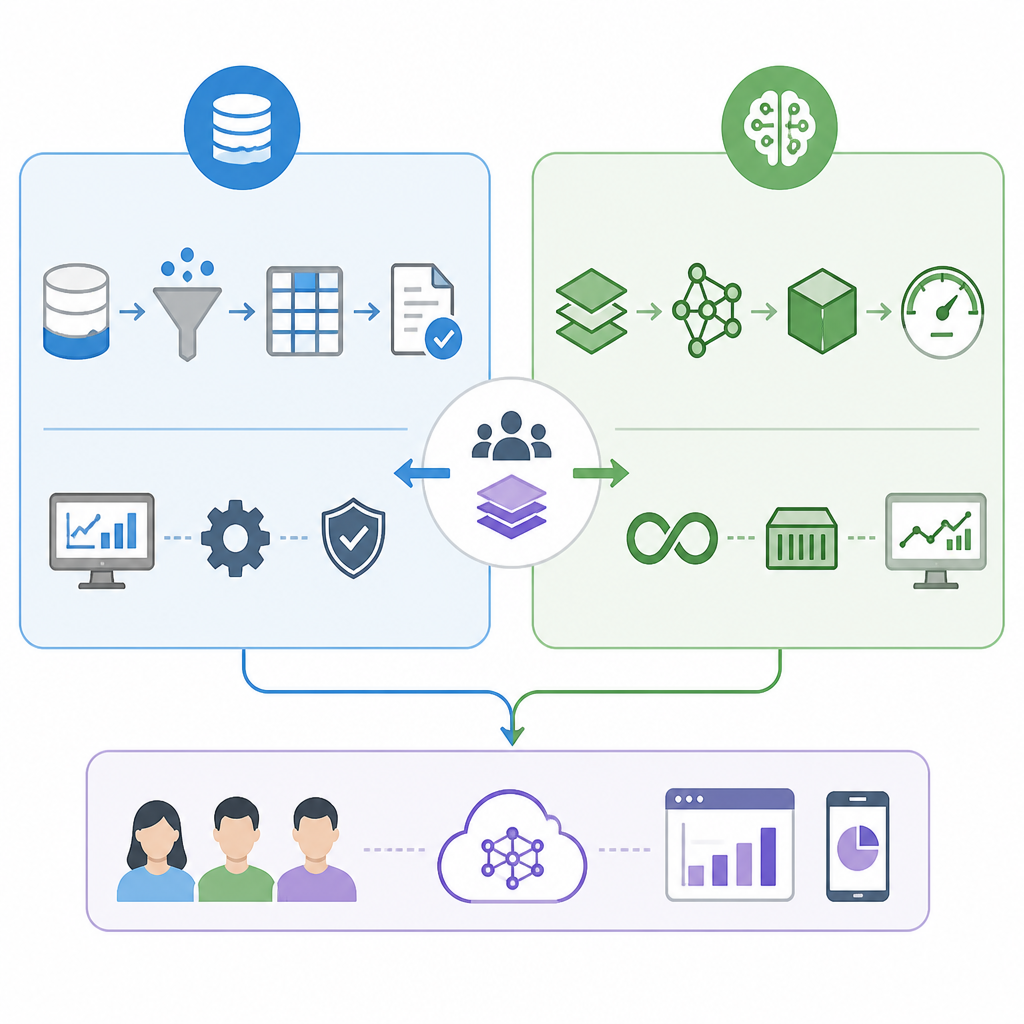
這也會改變團隊分工。當資料團隊、標註團隊與模型團隊沒有清楚邊界時,debug 成本會一路往後堆,最後變成誰都說得出問題、卻沒人能快速定位。
從產業角度看,模型本身越來越容易替換,真正拉開差距的是資料管線與治理紀律。換句話說,模型商品化後,資料作業就成了 AI 團隊的核心能力之一。
對需要上線 AI 功能的產品團隊,這篇文章其實在問一個很直接的問題:你有 MLOps,還是也有一個真正負責資料層的人?