Amazon Rekognition把審核變成過濾器
拆 Amazon Rekognition Content Moderation 的審核流程,整理成可直接套用的圖片與影片過濾模板。
這篇把 Rekognition 的內容審核拆成可直接複製的過濾流程。
我碰過太多 moderation pipeline,才知道有些東西看起來很簡單,實際上根本不是。紙面上很美:跑模型、抓壞內容、把邊界案例丟給人。真的上線後就變成災難。上傳量一多,誤判一堆,review queue 越積越像黑洞。我看過團隊自己手刻分類器、接一堆脆弱規則,最後還是回到原本那些人工工作。更慘的是,該擋的內容還是會漏進去,所謂自動化很多時候只是裝飾。
我這次拆的是 Amazon Rekognition Content Moderation。AWS 想賣的不是一個單點判斷,而是一整條流程:先機器標記,再讓人處理少數真的需要判斷的案例。這個方向我認同,因為它不神奇,但很務實。大多數團隊缺的不是更炫的 AI,是把髒活收斂掉的流程。
我還順手對照了 AWS Rekognition moderation docs、Amazon Augmented AI,以及 AWS 相關服務。真正值得拆的不是 API 本身,而是它要你接受的工作形狀:機器先篩、人類後判、政策規則放中間。
別把審核當成一個是非題
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Amazon Rekognition Content Moderation automates and streamlines your image and video moderation workflows using machine learning (ML), without requiring ML experience.
翻譯一下就是:AWS 賣的不是「這張圖安全不安全」這種二選一,而是一條可調的 moderation pipeline。這點很重要,因為很多團隊一開始就想錯。他們問的是「模型能不能告訴我這張圖能不能放行」,然後就做成 binary gate,最後再驚訝為什麼真實內容那麼髒、那麼模糊、那麼看情境。
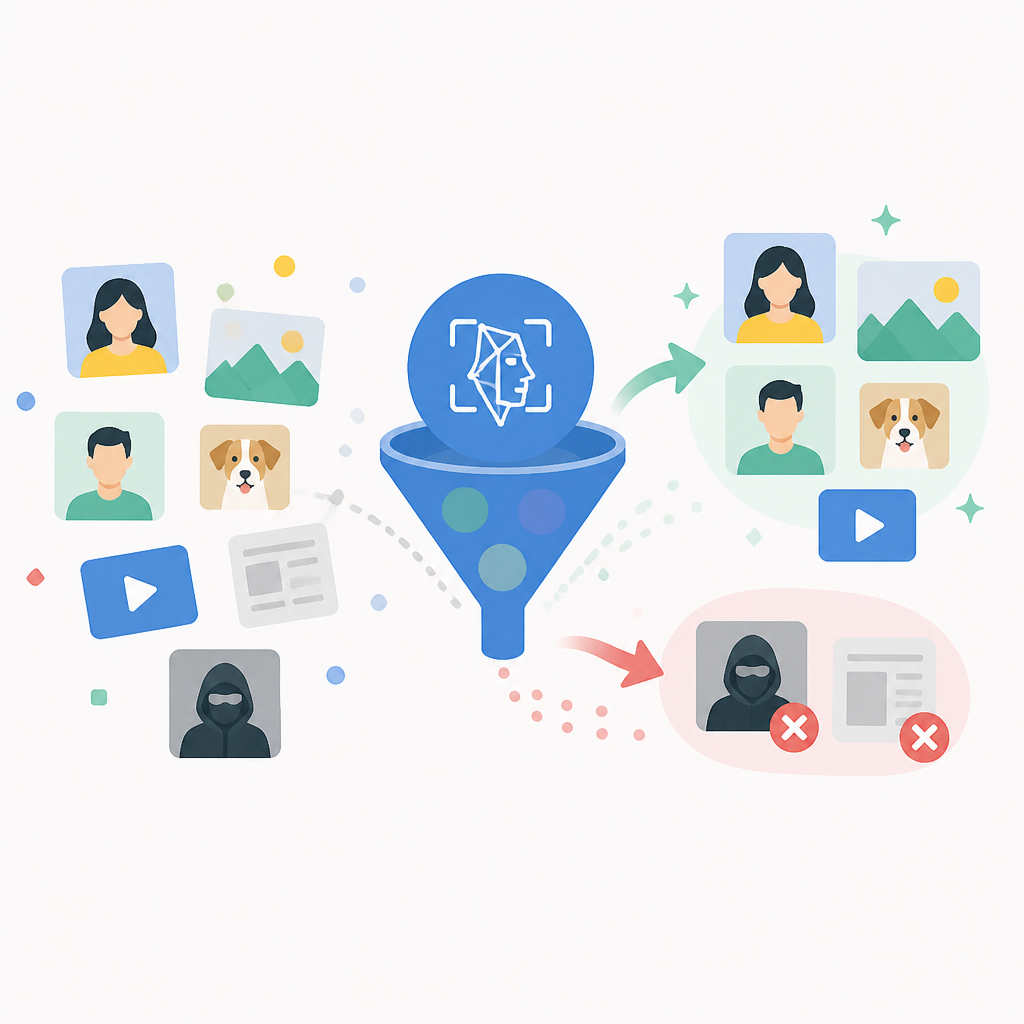
Rekognition 給你的不是單一答案,而是 labels、confidence scores,影片還有 timestamps。這個輸出形狀才有用。你可以把 policy 建在不同類別上,例如 explicit content、violence、drugs、tobacco、alcohol、hate symbols、gambling、disturbing content。不是全部塞進一個「bad」桶子。你可以做這種事:成人裸露直接擋,暴力先進 review,低 confidence 的酒精照片在某些產品情境下只標記不阻擋。
我之前做過一個 UGC 系統,團隊很愛一條硬閾值打天下。結果超荒謬:一張正常海邊照,因為模型 confidence 跟某些危險內容接近,就被當成同等級處理。後來我們把 policy 按類別拆開,整個系統才沒那麼智障。
實操寫法:先寫 moderation policy,再碰 API。把你在乎的類別列出來,定義每個 confidence band 要做什麼,哪些要 auto-block、哪些要 queue、哪些只記錄不動作。你如果跳過這步,Rekognition 只會變成另一個吵雜訊號。
- 把 labels 當 policy input,不要當最終真相。
- 每個類別用不同 threshold,不要全站一把尺。
- 輸出要能被 reviewer 和 ops 看懂,不然只是在製造新黑箱。
Confidence score 才是這東西真正值錢的地方
Mark each detected label and video timestamp with confidence scores.
這句很樸素,但我覺得它才是核心。confidence score 不是附加資訊,是你能不能把 moderation 調順的分水嶺。如果只有 label,你沒辦法校準自己的業務。如果有 confidence 加 timestamp,你就能把 review 介面直接跳到出事的那一秒。
影片尤其明顯。沒人想看 reviewer 在五分鐘影片裡拖來拖去找那一秒的爛內容。那是在浪費錢,也是在消耗 reviewer。timestamped detection 會把長片切成可處理的片段,讓人只看必要部分。
Rekognition moderation docs 裡有更細的輸出格式。如果你要上 production,先看文件再假設資料長相。AWS 的 demo 很大方,edge case 常常就沒那麼爽快。
我看過團隊把 confidence 當成宇宙真理,這真的很危險。95% 的 explicit flag 在交友 app 裡可能該直接擋;同樣 95%,放到醫療教育平台,也許就該進人審。數字有用,前提是你把它接到自己的 policy 上。
實操寫法:做一張簡單的 scoring matrix。每個 category 定義三段:auto-allow、review、auto-block。拿歷史內容回放測試 threshold。如果你沒有標註資料,就先 shadow review,對照模型輸出和人工決策。
- 影片 review 要能直接跳到 timestamp。
- threshold 要按類別拆,不要全域共用。
- 誤判和漏判要分開看,別混在一起算。
人審應該是窄門,不是第二份工作
Enable human reviewers to follow up on smaller subsets of content, and protect them from harmful content exposure by automatically flagging up to 95% of unsafe content.
這句如果在你的 workload 上真的成立,那不只是省錢而已,是在減少人每天盯垃圾內容的量。這件事我很在意,因為 reviewer fatigue 不是嘴上說說而已。人看太多爛東西,判斷會鈍,速度會慢,最後品質也會掉。
AWS 這裡把 Amazon Augmented AI 拉進來,意思很清楚:不是要把 reviewer 幹掉,而是把 review 變成例外處理。這才對。人應該處理模糊地帶、政策邊界、申訴,不該拿來做大量第一層篩選。如果軟體能先做,就先做。
我自己做過那種「模型有幫忙」的 queue,但 queue 裡還是滿滿顯而易見的垃圾。那種自動化最爛,因為它只增加複雜度,沒有減少痛苦。若 Rekognition 真的能先擋掉大多數 unsafe content,queue 才會小,人也才會做比較像人的工作。
實操寫法:把 queue 設計成 exception path。不要每個 upload 都送審,只送低 confidence、政策敏感類別、申訴案件。再把 queue 指標打開,看 auto-decide 和 escalated 的比例。如果 escalations 太高,不是 threshold 有問題,就是你的 category 切太粗。
自訂規則比模型 demo 更重要
Use a hierarchical taxonomy to create granular business rules for different geographies, target audiences, time of day, and more.
這段我很買單。模型有用,但真正讓 moderation 變成工作流的是 business rules。多地區產品不能用一把尺量全世界。某地可接受的內容,在另一地可能是限制級。成人白天能過的東西,青少年晚上就不一定行。
hierarchical taxonomy 的好處,是你不用整條 pipeline 重寫,就能把這種亂七八糟的現實塞進去。你不再只有一張 flat 的 unsafe list,而是可以做 policy layer。這讓 product、legal、trust & safety、engineering 至少有共同語言。老實說,這通常才是最難的地方。
AWS 一直提 geography、target audience、time of day,不是廢話。他們其實在講:moderation 本來就是情境式的。如果你的規則還分不出兒童 app 跟夜生活 app,那你的政策成熟度就還很低。
實操寫法:把 detection 跟 policy 分開。讓 Rekognition 產生 labels,然後再映射到你自己的 policy engine。地區、年齡門檻、產品 surface、使用者狀態都放在模型外面。這樣你改政策,不用重訓模型。
- 每個地區或法規框架各自一層 policy。
- 年齡規則和內容標籤分開管理。
- 把 policy decision 存起來,之後才有 audit 依據。
影片審核才是真正會痛的地方
Process millions of images and videos efficiently while detecting inappropriate or unwanted content.
圖片很煩,影片更煩。每一秒都可能有不同 moderation event,如果系統抓不到問題從哪一秒開始,review 成本會爆。這也是為什麼 timestamp 和 confidence 那麼重要,它們把一大坨資料變成可處理的事件序列。
AWS 頁面也提到社群、遊戲、電商、廣告、媒體娛樂這些場景。這些不是裝飾用案例,這些地方最容易先爆,因為 UGC 量大、影片多、使用者又很會鑽漏洞。一旦你有直播、短片、avatar、留言一起進 moderation flow,舊的人工流程通常直接死掉。
我看過一個運動平台想用純人力審短片,完全行不通。reviewer 還沒看到,影片早就被分享、被檢舉、被吵成三個群組的戰場。唯一的出路,就是先自動過濾,再把人留給怪東西。
實操寫法:把影片當事件流,不要當檔案。把 detection 結果連同 timestamps 存好,review 工具要能直接跳到 flagged segment。如果你是用 Amazon S3、AWS Lambda、AWS Step Functions 串起來,moderation job 最好做成非同步,別讓上傳卡住使用者體驗。
真正的價值是少看垃圾,不是多一層 AI 表演
Create cost-reliable, scalable, and repeatable cloud-based content moderation workflows without upfront commitments or expensive licenses.
這句其實是 AWS 直接對 ops 跟 finance 講話,我懂。很多 moderation 一開始是安全專案,後來變成預算黑洞。review 人力一直加,工具一直補,法務要 audit trail,產品要更快放行。大家都想要同一件事,但沒人想扛整條 pipeline。
Rekognition 的賣點是按 image 或 video duration 計費,基礎設施有人管,不用自己先養一套 ML stack 只為了篩 UGC。對小團隊,或 moderation 只是眾多需求之一,這很有吸引力。
但我會很小心不要把它講成「設定一次就好」。不是。你的 policy 會漂移,category 會要調,reviewer 會抓到模型看不懂的邊界案例。真正的勝利不是把人拿掉,而是把明顯垃圾擋在前面。
實操寫法:把 moderation 當 workflow 量,不要只看 API call。追四個數字:多少自動處理、多少進人工、review 花多久、policy 改了幾次。如果這四個你都看不到,你根本不知道系統是在幫忙,還是在搬工作。
可抄的模板
# Amazon Rekognition 內容審核工作流模板
## 1) Policy table
先定義你的類別、閾值和動作。
| Category | Confidence band | Action | Notes |
|---|---:|---|---|
| Explicit adult content | 90-100 | Auto-block | 不進人工審核 |
| Violence | 70-100 | Queue for review | 直接跳到 timestamp |
| Drugs | 80-100 | Queue for review | 依地區政策調整 |
| Hate symbols | 85-100 | Auto-block | 保留 audit log |
| Gambling | 75-100 | Review | 只在年齡限制場景啟用 |
| Disturbing content | 70-100 | Review | 敏感 surface 優先 |
## 2) Processing flow
1. 使用者上傳圖片或影片。
2. 存到 S3。
3. 觸發 moderation job。
4. 把媒體送到 Amazon Rekognition Content Moderation。
5. 存下 labels、confidence scores、timestamps。
6. 用自己的 policy layer 做路由。
7. 自動放行、自動阻擋或送人審。
8. 低 confidence 或政策敏感案例送 Amazon A2I。
9. 記錄最終決策,供 audit 和 threshold tuning。
## 3) Reviewer queue rules
- 只送模糊案例給人。
- 直接跳到被標記的影片時間點。
- 能模糊就模糊,別讓 reviewer 先看見明顯有害預覽。
- First-pass review 和 appeals 分開。
- 追蹤每個 category 的 reviewer disagreement。
## 4) Example policy logic
IF category = explicit_adult AND confidence >= 90
THEN block
ELSE IF category = violence AND confidence >= 70
THEN queue_review
ELSE IF category = hate_symbol AND confidence >= 85
THEN block
ELSE IF confidence < threshold_for_category
THEN allow_or_log
ELSE
queue_review
## 5) Ops metrics to watch
- Total uploads processed
- % auto-allowed
- % auto-blocked
- % sent to human review
- Average review time
- Reviewer disagreement rate
- False positive rate by category
- False negative rate by category
## 6) Minimal implementation notes
- Detection 和 policy 分開。
- Threshold 按 category 設。
- 影片一定要存 timestamps。
- 地區與年齡門檻放在模型外面。
- 每次 policy 改動都重測 threshold。
## 7) Copy-ready reviewer brief
我們會自動掃描上傳的圖片與影片,找出不安全內容。
只有模糊或政策敏感的案例才會進人工審核。
Reviewer 請根據標記的 label、confidence score 和 timestamp 做最終判斷。
所有最終決策都必須記錄,供 audit 與 tuning 使用。
這段就是我會先抄的版本。它不花俏,因為 moderation 本來就不該花俏。你越少把自訂邏輯埋進工具裡,之後要調整就越不痛。
如果你想走 AWS 原生路線,基本組合就是 Amazon Rekognition 做 detection、Amazon A2I 做 human review,再加上你自己的 policy layer 做 routing。若你真的需要超出內建分類的客製 moderation,再看 Amazon Rekognition Custom Labels。但我會把它排在後面,先把 built-in taxonomy 用乾淨再說。
AWS 頁面上提到的 CoStar Group、Dream11、SmugMug、ZOZO Inc.,其實都在講同一件事:高流量上傳、安全需求、把人留給例外。這才是重點,不是產品文案。
來源:https://aws.amazon.com/rekognition/content-moderation/。我把 AWS 的產品說法和流程重寫成台灣開發者比較好直接抄的版本;產品能力與案例來自 AWS,流程拆解、policy framing 和模板是我整理的。