ClinHallu 追蹤醫療 MLLM 幻覺來源
ClinHallu 把醫療多模態模型的幻覺拆成看圖、記知識、做整合三段來診斷,讓開發者能定位錯誤來源。

ClinHallu 把醫療多模態模型的幻覺拆成看圖、記知識、做整合三段來診斷。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:7,031 筆驗證樣本
- 突破點:三階段幻覺診斷
醫療多模態大型語言模型,真正難的不是「會不會答」,而是「它為什麼會答錯」。這篇 ClinHallu 的重點,就是把醫療 MLLM 的幻覺來源拆開看:錯在看圖、錯在醫療知識,還是錯在把兩者整合成答案的最後一步。
這種拆法很實際。因為如果你只看最後答案對不對,很多問題會被混在一起。模型可能圖片看錯,也可能是醫療常識抓錯,甚至前兩步都沒問題,卻在綜合推理時翻車。ClinHallu 想做的,就是把這些失誤點標出來,讓研究者和工程團隊知道該修哪一段。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要裡明講,現有醫療幻覺 benchmark 多半偏向蒐集例子,但沒有把模型的推理路徑一起追出來。這會讓除錯變得很盲。你知道模型錯了,卻不知道是視覺辨識不行、知識召回不準,還是整合步驟出問題。
對醫療場景來說,這種模糊性特別麻煩。因為同樣是答錯,背後可能是完全不同的工程問題。若錯在視覺模組,改善方向可能是影像編碼器;若錯在知識,可能要調 grounding 或微調資料;若錯在推理整合,則可能要改提示詞或訓練策略。單一分數看不出這些差異。
ClinHallu 的定位,就是把「幻覺」從一個總分,改成可追蹤的來源分析工具。這讓 benchmark 不只是排名用,而是診斷用。
ClinHallu 怎麼運作
這個 benchmark 收錄 7,031 筆驗證過的樣本,並替每筆資料加上結構化的推理軌跡。這條軌跡被切成三段:Visual Recognition、Knowledge Recall、Reasoning Integration。也就是先看圖,再找知識,最後整合成答案。
核心想法很直白:不要把模型當黑盒。若影像內容被誤讀,問題就落在 Visual Recognition;若模型把醫療事實記錯,問題就出在 Knowledge Recall;若前兩步都還行,但最後結論歪掉,則是 Reasoning Integration 出錯。
這樣的切法,讓研究者不只看結果,還能看過程。對醫療 MLLM 來說,這比單純判斷對錯更有用,因為它能把錯誤分類到不同層級,方便後續做針對性修正。
摘要也提到 stage-replacement interventions。白話說,就是把某一階段修正後,再觀察最後輸出會不會跟著變。這種做法的價值在於,它不只是標註相關性,而是在測試某個階段的修正,是否真的會影響最終答案。換句話說,它試著把「哪裡錯」跟「改哪裡有用」連起來。
論文實際證明了什麼
先講限制:摘要沒有公開完整 benchmark 數字,也沒有列出 accuracy、leaderboard 或和其他方法的逐項比較。所以如果你期待看到一串明確分數,這份摘要沒有提供。
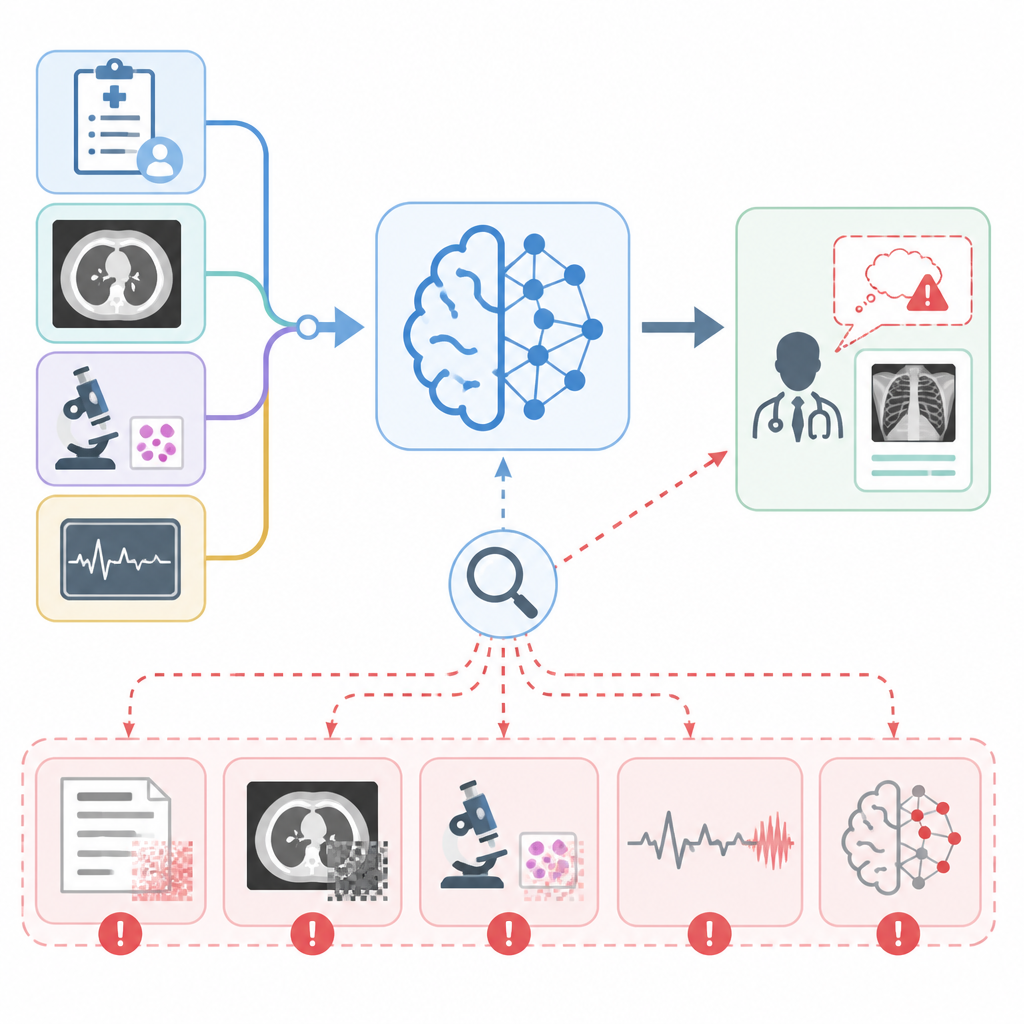
但它至少清楚講了兩件事。第一,幻覺來源不是單一的。不同樣本的失誤可能發生在不同階段,所以用一個總分概括,資訊量太低。第二,分階段診斷是可行的。ClinHallu 不是只收集錯誤案例,而是把錯誤對應到三段推理流程,讓來源分析變得具體。
摘要還指出,trace-supervised fine-tuning 能降低 stage-wise hallucinations。這是重要訊號,因為它代表這些推理軌跡不只是診斷標籤,也能拿來當訓練訊號,幫模型改善行為。不過摘要沒有說降幅多少,所以這裡看得到方向,看不到幅度。
- 7,031 筆驗證樣本,足以支撐分階段分析。
- 三段式推理軌跡,能把視覺、知識、整合錯誤分開。
- trace-supervised fine-tuning 被用來降低分階段幻覺。
對開發者有什麼影響
如果你在做醫療 MLLM,ClinHallu 提供的是一種更可操作的 debug 方式。模型答錯時,不用只問「為什麼胡說」,而是可以問:它是看錯影像、記錯醫療知識,還是整合證據時出問題?這三個答案對應的修法完全不同。
這對臨床應用尤其重要。醫療模型有時表面上看起來答得很穩,最後答案也常常對,但內部其實可能一直在某個階段失真。若沒有分層診斷,你很難知道模型到底是穩定,還是只是剛好蒙對。ClinHallu 的價值,就是把這種脆弱性攤開。
對訓練流程來說,這篇也傳達一個訊息:資料不一定只能拿來教模型「答對」,也可以教它「怎麼答」。如果 trace supervision 真的能減少 stage-wise hallucination,那未來的訓練資料設計,可能會更重視推理結構,而不是只追求最後 token 的正確性。
這篇沒說清楚的地方
摘要沒有交代幾個實作上很關鍵的細節。像是它涵蓋哪些醫療影像任務、資料模態有哪些、推理軌跡怎麼驗證、以及和既有方法相比到底差多少,摘要都沒展開。這些資訊如果要評估能不能落地,還是得看完整論文。
另外,摘要也沒有說 stage-wise interventions 是否能跨模型家族、跨臨床領域泛化。這代表 ClinHallu 目前比較像一個診斷框架,而不是已經證明可直接部署的完整解法。它比較擅長幫你看清楚問題在哪,不是直接保證把問題修好。
即便如此,這篇的方向仍然很清楚:它把醫療幻覺分析從「有沒有錯」推進到「錯在哪一段」。對做可信任醫療 AI 的團隊來說,這種分層觀察工具,通常比單一分數更接近真正需要的除錯方式。
如果你正在評估醫療多模態模型,ClinHallu 提醒的一件事是:最後答案準,不代表整條推理鏈都健康。對開發者而言,能定位錯誤來源,往往比只看總分更有價值。