EEVEE 讓提示學習更適合真實資料流
EEVEE 把 test-time prompt learning 做成可處理多資料集的框架,靠路由與提示共演化,降低跨資料集干擾。
EEVEE 把 test-time prompt learning 做成可處理多資料集的框架,靠路由與提示共演化,降低跨資料集干擾。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:平均多 benchmark 分數提升 10.38 與 24.32 分
- 突破點:路由器分群再共演化
這篇論文在講一件很實際的事:如果 LLM agent 要在真實環境裡持續學習,光會在單一資料集上調 prompt 還不夠。EEVEE 想解的,是多資料流混在一起時,原本很容易互相干擾的 test-time prompt learning 問題。
EEVEE: Towards Test-time Prompt Learning in the Real World for Self-Improving Agents 提出一個多資料集的 test-time prompt learning 框架。它不是只追求某個單一 benchmark 的分數,而是把 heterogeneous task streams 當成主要場景,讓 agent 在測試階段也能持續調整 prompt,還盡量不讓不同任務彼此污染。
這個方向對開發者很有感。因為真實世界的流量本來就不乾淨,不會乖乖照著資料集切好。客服、站內搜尋、內部工具、領域問答,常常會一起進來。EEVEE 的重點,就是要讓 prompt learning 在這種混雜輸入下還能工作。
它想解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要講得很直接:現有的 test-time prompt learning 方法,多半是為單一資料集設計的。這種設定在實驗室很合理,因為資料分布單純,評估也清楚。但一旦把系統放進真實服務,輸入流就會變得很雜。

問題出在這裡。當不同領域、不同任務型態、不同資料集的樣本混在同一條流裡時,提示更新不再只是「學得更好」而已,還可能變成「互相干擾」。前一批資料剛調好的 prompt,下一批資料可能就把它拉歪。
EEVEE 要處理的,就是這種跨資料集干擾。它不是假設所有輸入都屬於同一個分布,而是明確承認真實世界本來就混雜。這也是為什麼這篇看起來像是在談 prompt learning,實際上更像是在談一個線上適應系統要怎麼維持穩定。
從摘要能看出的另一個重點是,作者把這個限制視為 prior work 的主要弱點。也就是說,過去的方法可能在單一 benchmark 上表現不錯,但不代表能平順地搬到多資料流環境。EEVEE 的定位,就是把這個落差補起來。
EEVEE 的方法怎麼運作
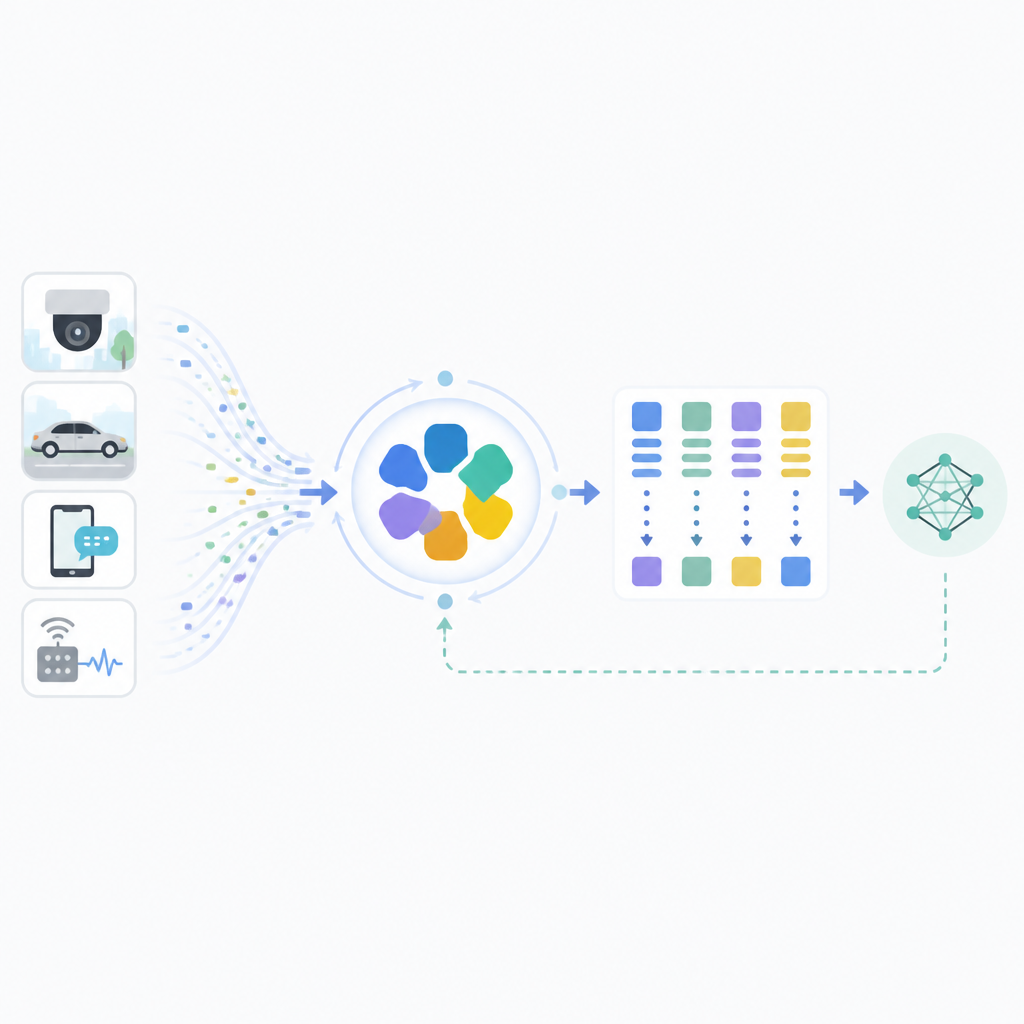
EEVEE 的核心設計,是在 prompt learning 前面加上一個 router。這個 router 先把輸入分到不同的 task clusters,再把不同群組送到比較合適的 prompt 配置。
白話一點說,它不是讓所有新資料都直接去改同一組 prompt,而是先做分流。這樣做的目的,是減少不同資料集之間的相互污染。相關的輸入放一起,不相干的輸入分開處理,更新就比較不容易打架。
摘要還提到一個更關鍵的概念:router 和 prompt 不是分開優化,而是共演化。論文把這件事描述成交錯的 router learning 與 prompt learning phases。意思是,路由器怎麼分群,會影響 prompt 怎麼學;prompt 學得怎樣,也會反過來影響路由器怎麼判斷。
這個設計其實很符合真實系統的直覺。你很難先把路由完全定死,再獨立去調 prompt;因為分類結果和 prompt 狀態本來就是互相依賴。EEVEE 的做法,是把這兩件事綁在一起輪流更新,而不是假裝它們能被單獨最佳化。
如果從系統角度看,它像是一個線上控制迴圈:先辨識輸入屬於哪類任務,再更新對應的 prompt,接著根據結果修正路由策略。這不是單純的 prompt tuning 小技巧,而是把資料分流納入學習流程的一部分。
論文實際證明了什麼
摘要有提到,作者是在多個資料集上做實驗。不過,這份來源沒有公開完整 benchmark 細節,所以我們只能確認它是多資料集、多 benchmark 的評估方向,不能再往下補沒出現在摘要裡的數字或資料集名稱。
能確定的結果,是 EEVEE 在平均多 benchmark 分數上有明顯提升。相較於 Qwen3-4B-Instruct,平均提升 10.38 分;相較於 DeepSeek-V3.2,平均提升 24.32 分。這代表它不是只在單一任務上小幅進步,而是在跨 benchmark 的平均表現上拉開差距。
摘要也說,EEVEE 相比 SOTA 方法 GEPA 和 ACE,最高可提升 37.2% 與 48.2%。這個數字很醒目,至少說明作者的主張不是「差不多」,而是希望在 heterogeneous streams 這種難場景裡,做出明顯優勢。
但也要注意,摘要沒有提供每個資料集的拆分結果,也沒有 latency、計算成本、router 開銷這類實作指標。換句話說,公開摘要能讓我們看到方向和相對提升,但還看不到這些提升是不是平均分布在所有任務上。
所以這篇論文目前能被證明的,是一個很明確的結論:當 test-time prompt learning 面對多資料集混流時,把路由和 prompt 更新綁在一起,確實能改善平均表現。至於它在更細的條件下表現如何,摘要沒有給完整答案。
對開發者有什麼實際影響
如果你在做會「邊跑邊學」的 agent,這篇的啟發很直接:不要把所有新樣本都當成同一個池子。真實流量通常不是單一分布,硬把它們混在一起,prompt 更新很容易變成互相抵銷。
EEVEE 的 router-first 思路,提供了一個很實用的架構觀點。它等於在說,先做任務分離,再做共享狀態更新,可能比直接對整條流做 prompt adaptation 更穩。對需要持續適應的系統來說,這種分流機制本來就常見,只是這篇把它明確放進 test-time prompt learning 裡。
這對幾種場景特別有參考價值。像是個人化 agent、持續學習的對話系統、或是會接觸多種工作流的內部工具。只要你的輸入不是乾淨單一的 benchmark,而是會混雜不同任務,這篇的設計就很值得看。
不過,限制也很明顯。摘要沒有說 router-prompt 共演化的額外成本,也沒有說 task clustering 的品質有多敏感。若路由分群做不好,理論上還是可能把任務切錯,反而影響 prompt 更新。這些風險在摘要裡都還沒被完整展開。
摘要也沒有給出分資料集的細節,所以我們無法判斷提升是不是來自少數資料集,或是整體都穩定進步。對工程團隊來說,這代表它是一個很有方向感的框架,但要不要真的落地,還得看完整論文裡的實驗設計與系統成本。
可以怎麼理解這篇工作的價值
EEVEE 不是在發明一種全新的 prompt 概念,而是在修正 prompt learning 的使用場景。它把問題從「單一 benchmark 上怎麼學得更好」拉到「真實資料流裡怎麼學得不互相傷害」。
這個轉向很重要。因為很多方法在論文裡看起來有效,一旦進到多任務、混流、持續更新的環境,就會開始掉分。EEVEE 的貢獻,是把路由和 prompt 適應一起考慮,讓系統更貼近 production data 的樣子。
如果只用一句話總結,這篇證明的是:test-time prompt learning 要走出實驗室,不能只靠更強的 prompt,還得先把輸入分流做好。EEVEE 把這個直覺做成了可操作的框架,並且在多 benchmark 平均表現上拿到實際提升。
對開發者來說,這篇最值得記住的不是某個單點技巧,而是一個架構原則:當你的 agent 要在混雜流裡自我改善,路由可能不是前處理,而是學習本身的一部分。
- 它把 test-time prompt learning 從單一資料集,推向多資料流場景。
- 它用 router 分群,再讓 router 和 prompt 交錯共演化。
- 它的公開摘要已顯示多 benchmark 平均分數有明顯提升,但細部 benchmark 與成本資訊尚未公開。