具身智能的钱正在往大脑集中,泡沫也在集中
我認為具身智能現在最值得押注的不是本體,而是大腦、世界模型與數據基礎設施;資本正在往這裡集中,泡沫也一起集中。

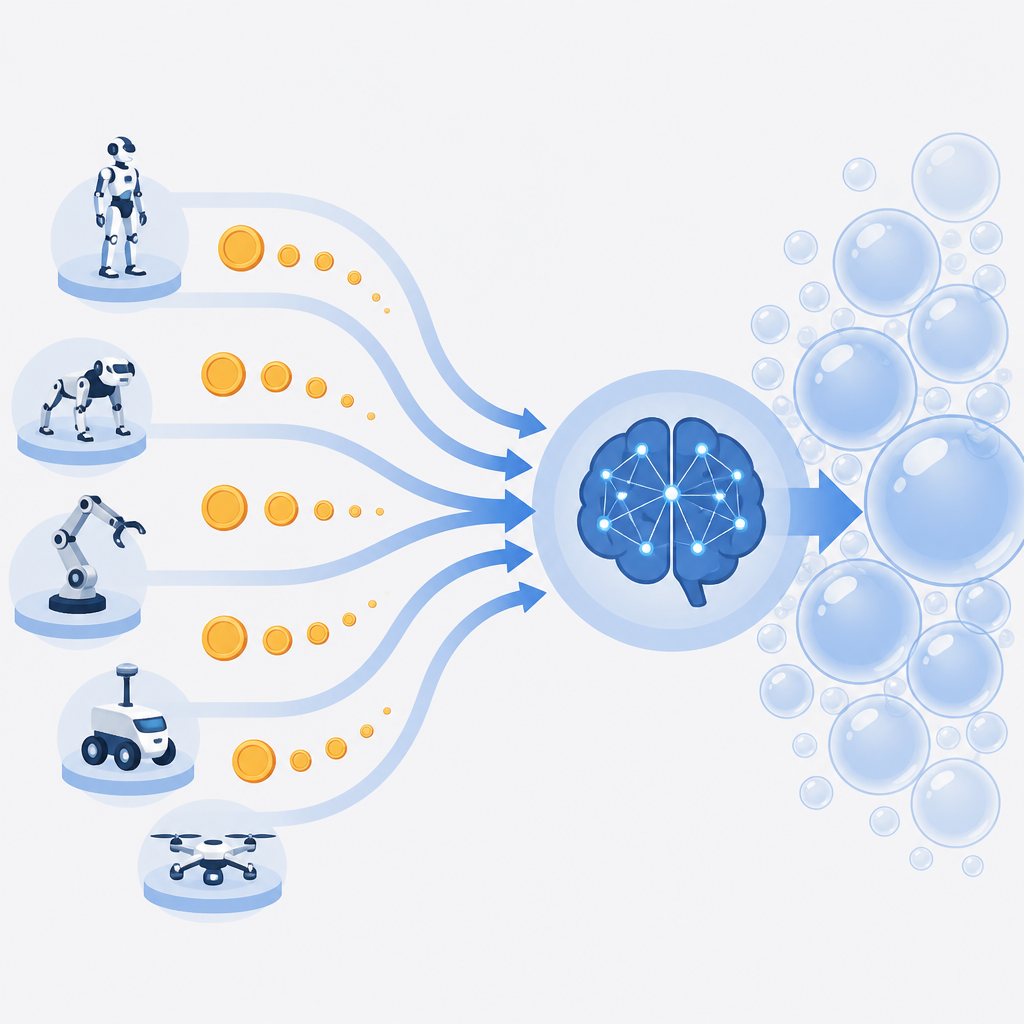
具身智能的資本正在往大腦、世界模型和數據基礎設施集中。
我認為具身智能當前最值得押注的不是本體,而是大腦與數據基礎設施。量子位統計顯示,2026年上半年國內具身智能賽道融資約438億元,超過一半流向「大腦派」公司;同期本體派只占12.8%,甚至低於零部件公司。這不是短期噪音,而是資本對行業價值分配的重新定價:硬體決定能不能做,大腦決定能不能規模化複製。
第一個論點:資本已經把「上限」押在大腦上了
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
投資人那句「本體兜住下限,大腦決定上限」,不是口號,是資金流向的真實寫照。Pre-A輪平均7億元,B輪平均22.5億元,這種量級放在多數行業裡已經接近C輪、D輪。它石智航Pre-A輪拿到4.55億美元,千尋智能在2月至6月連融四輪、累計近50億元,說明市場不再按傳統里程碑定價,而是按「誰更像未來的機器人作業系統」定價。

背後邏輯也很直接。機器人本體當然重要,但它更像製造業問題,考驗供應鏈、成本和量產;大腦則更像AI問題,邊際成本低、複用性強、遷移性高。中國在製造端有天然優勢,意味著本體會快速進化,但真正能拉開估值差距的,還是誰先把感知、推理和行動串成閉環。資本追逐的是可複製的能力,而不是一台機器的單點性能。
第二個論點:世界模型正在取代VLA成為新敘事中心
今年上半年有融資動態的35家「大腦派」公司裡,27家在研發世界模型,占比接近八成,這個數字說明賽道共識已經發生遷移。2024年大家還在比誰的VLA更強、誰的真機數據更多;到了今天,不做世界模型似乎就像沒跟上時代。它不只是技術路線變化,更是融資語言變化,因為「世界模型」比「VLA」更能承接想像空間,也更容易讓投資人相信公司在做下一代平台。
但真正重要的不是名詞,而是底層實現。蒋子元的判斷很有代表性:很多所謂世界模型,本質上只是把影片生成模型作為backbone,而VLA更多依賴語言模型作為backbone。換句話說,路線之爭沒有外界想得那麼硬,創業公司會不斷切換更順手的架構。就像影片生成從U-Net轉向DiT,行業不會為一種範式守身如玉,誰能更快把效果做出來,誰就會成為「正確路線」。
第三個論點:決定勝負的不是路線潔癖,而是數據基礎設施
自變量機器人算法負責人甘如饴說得更到位:比起世界模型還是VLA,底層的數據基礎設施才是核心競爭力。這套基礎設施覆蓋數采、訓練和評測全流程,目標不是做一次漂亮演示,而是形成可規模化運轉的工業級體系。這個判斷比任何路線宣言都更接近現實,因為機器人真正難的地方,從來不是寫出一個demo,而是讓模型在不同場景裡持續穩定地變強。
這也是為什麼「能不能快速趕上」不取決於今天站在哪條路線,而取決於有沒有把數據管道、評測體系和訓練閉環先搭好。技術架構會變,今天的世界模型明天可能被更新範式替代,但數據資產不會憑空出現。誰先把真實世界的數據採集、標註、回放、訓練和評測做成流水線,誰就擁有跨架構遷移的能力。對創業公司來說,這比押注某個名詞更重要。
反方可能怎麼說
最強的反對意見很簡單:具身智能現在估值太高、融資太快、路線太散,泡沫遲早會破。這個擔心不是空穴來風。行業自己也承認,90%以上的公司可能會消失,而且泛化性如果不能兌現,真正可落地的場景會非常有限。與大模型相比,具身智能的商業化確定性更低,今天砸進去的錢,確實有相當一部分可能打水漂。
但我不接受「因此現在不該投」的結論。早期產業發展需要泡沫來聚集資本、人才和注意力,這一點在大模型時代已經被驗證過。不同的是,具身智能還沒收斂到只剩幾條清晰賽道,所以最優策略不是回避,而是承認它是高波動、高淘汰率的窗口期。問題不在於有沒有泡沫,而在於你是否把泡沫當成確定性,把故事當成結果。
你能做什麼
如果你是工程師,就別被「世界模型」三個字綁架,先把數據管道、評測集和閉環訓練做扎實;如果你是PM,就盯住可複用場景和失敗邊界,不要把演示當產品;如果你是創辦人,就把融資當作搶時間而不是講故事,盡快建立能跨架構遷移的數據資產和人才密度。這個賽道最後贏的,不是最會喊口號的人,而是最快把不確定性工程化的人。