LLM 維護的 wiki 比原始 RAG 更適合真正的知識工作
我主張,LLM 維護的 wiki 比原始 RAG 更適合知識工作,因為它能累積、保持更新,還能保留決策脈絡。

LLM 維護的 wiki 比原始 RAG 更適合知識工作,因為它會累積知識而不是每次重算。
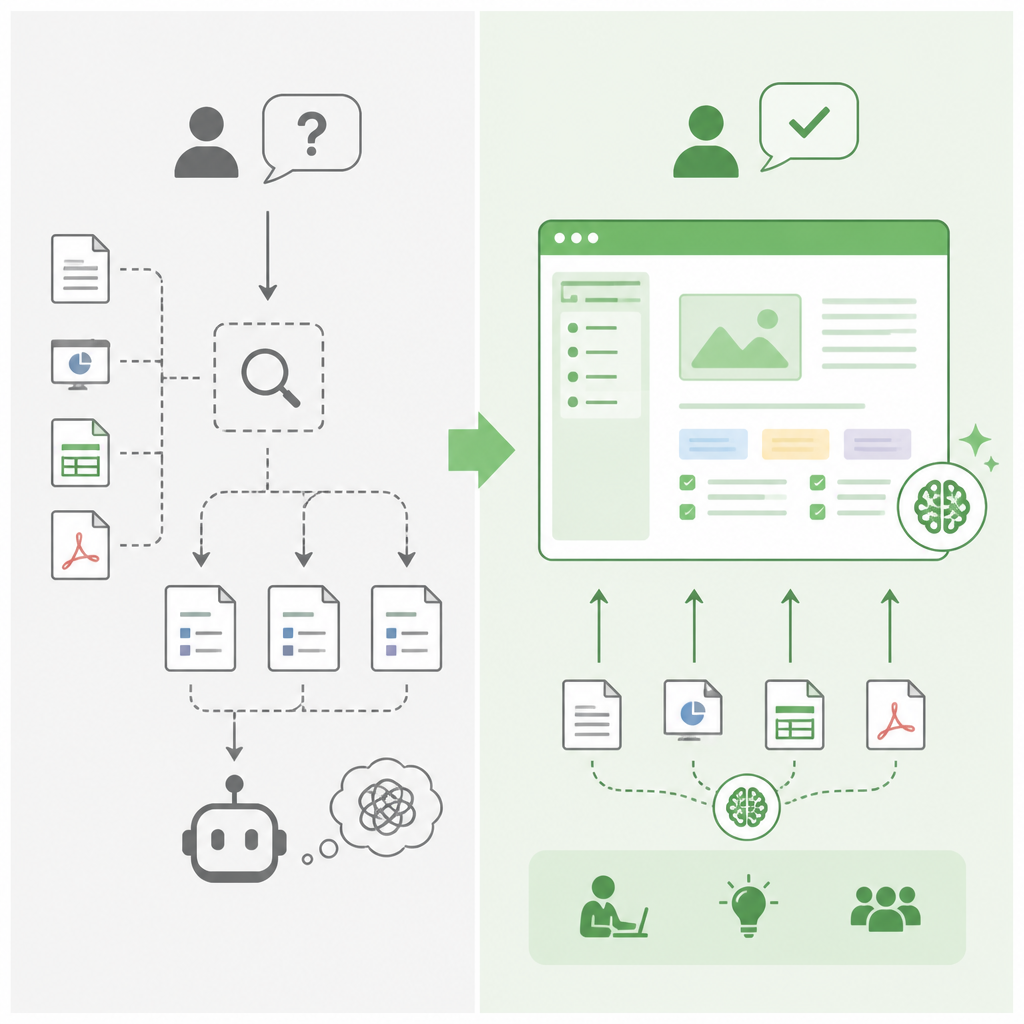
我站在這一邊:真正有價值的知識系統,不是更大的檢索索引,而是由 LLM 持續維護的 wiki。原始 RAG 只能在提問當下把相關片段撈出來,卻不會記住自己已經學到什麼、否決過什麼、上一輪哪個綜合結論被採納。把來源、查詢與修正持續寫回 wiki,才會把一次次工作轉成可累積的結構。這不是搜尋工具升級,而是系統本身開始有記憶。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
原始 RAG 的上限是「召回」,不是「理解」。它擅長把對的 chunk 撈出來,卻不擅長把五篇論文、三份會議記錄和一串客訴訊息整合成可重用的結論。只要問題稍微複雜一點,模型每次都得從頭拼一次答案,結果是同一批資料被反覆閱讀、同一組關係被反覆重建。

這種浪費在日常工具裡已經很明顯。像 NotebookLM、ChatGPT 檔案上傳這類系統,單次問答可以很驚艷,但下一次問相關問題時,仍要重新讀同樣的材料。若一個產品每次都要把已知事實重新算一遍,它就不是知識庫,而是重複運算費用表。知識工作要的是累積,不是反覆啟動。
第二個論點
更好的模型,是讓 LLM 一邊讀,一邊把知識寫回 wiki。每新增一份來源,就更新實體頁、強化主題摘要、標記矛盾、補上交叉連結。Karpathy 提到的核心直覺很重要:知識應該被編譯一次並持續維護,而不是每次查詢都重新推導。這使系統更像軟體,而不是聊天紀錄。
實務上的好處是輸出可以沉澱成資產。今天模型產出一張比較表、一段產品論證或一份研究綜整,這些內容應該回寫進 wiki,否則最好的工作只會消失在對話視窗裡。若系統能把每次嚴肅提問都變成下一次更快的起點,研究、競品分析、長期產品探索就會開始複利。這種複利才是知識工作的真正效率來源。
反方可能怎麼說
最有力的反對意見是:由 LLM 維護的 wiki 可能比原始 RAG 更容易把錯誤固化。模型一旦誤讀來源、寫下錯摘要,還把摘要層層傳播到連結頁面,錯誤就會變得很黏。相較之下,原始檢索至少保留了原文,還能讓人回頭核對。對高風險領域來說,這不是小問題。
另一個反對理由是規模。小團隊、單一專案時,一個索引檔加幾個 markdown 頁面就夠了;但資料一多,還是需要搜尋、來源追蹤與審核流程。wiki 不是 source of truth 的替代品,也不是人類判斷的替代品。它只是建立在原始語料上的一層整理,不是把現實壓縮成魔法。
但這些限制不推翻這個方向,反而定義了正確做法:wiki 必須明確標示為衍生層、可修訂、可稽核。原始來源保持不可變,wiki 保持可編輯;錯誤因此可見、可回溯、可修正,而不是被藏在聊天歷史裡。風險不是理由去堅持 raw RAG,風險是理由把 wiki 設計成有來源、有版本、有審核的維護型資產。
你能做什麼
如果你是工程師、PM 或創辦人,別再把 LLM 當成一次性回答機器,而要把它當成知識庫的維護工。保留原始來源不動,另外建立一層 wiki 做綜整,再加一份決策與死路的日誌,避免系統重複犯同樣的錯。先從一個領域、一個索引、一條 ingest 流程開始;只要模型能更新頁面、標記矛盾、保留推理脈絡,你就已經做出比聊天更有價值的東西:一個會複利的團隊記憶。