OCR 4 把 PDF 變成可引用 RAG 輸入
拆 Mistral OCR 4 怎麼把亂 PDF 變成有順序、可引用、適合 RAG 的輸入,連 bounding box、語言支援和模板都一起整理好。

OCR 4 能把亂 PDF 變成有引用來源、可直接丟進 RAG 的資料。
我做文件管線做到現在,最煩的不是抽不出字,是抽出來之後整份資料像被攪爛。表格變成一坨、腳註亂飛、圖片順序不對,最後丟進搜尋或 RAG,模型還一臉正經地引用錯段落。你看起來像把文件「處理完」了,實際上只是把問題換個地方放。我以前也很愛這種假進度,直到使用者開始拿截圖問我:你這答案到底從哪裡來的?
這次讓我停下來看的,是 AI Business 寫的 Mistral OCR 4 文章,作者是 Esther Shittu。它不是在吹「OCR 更準」這種老梗,而是直接把重點放在文件理解、引用、結構保留,這些才是做 RAG、內部搜尋、文件助理時真的會痛到的地方。
OCR 不是重點,保住文件原貌才是
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
“What OCR typically does is just pull stuff out… It does not really look at it and understand it. Whereas this is saying we understand it.”
這句是 Omdia 分析師 Mark Beccue 講的,我覺得很準。傳統 OCR 的思路很土:先把字撈出來,其他再說。問題是文件不是純文字,它有閱讀順序、有欄位、有表格、有圖說、有註解。你一旦把這些打散,後面的模型再聰明也只能在碎紙堆裡找線索。
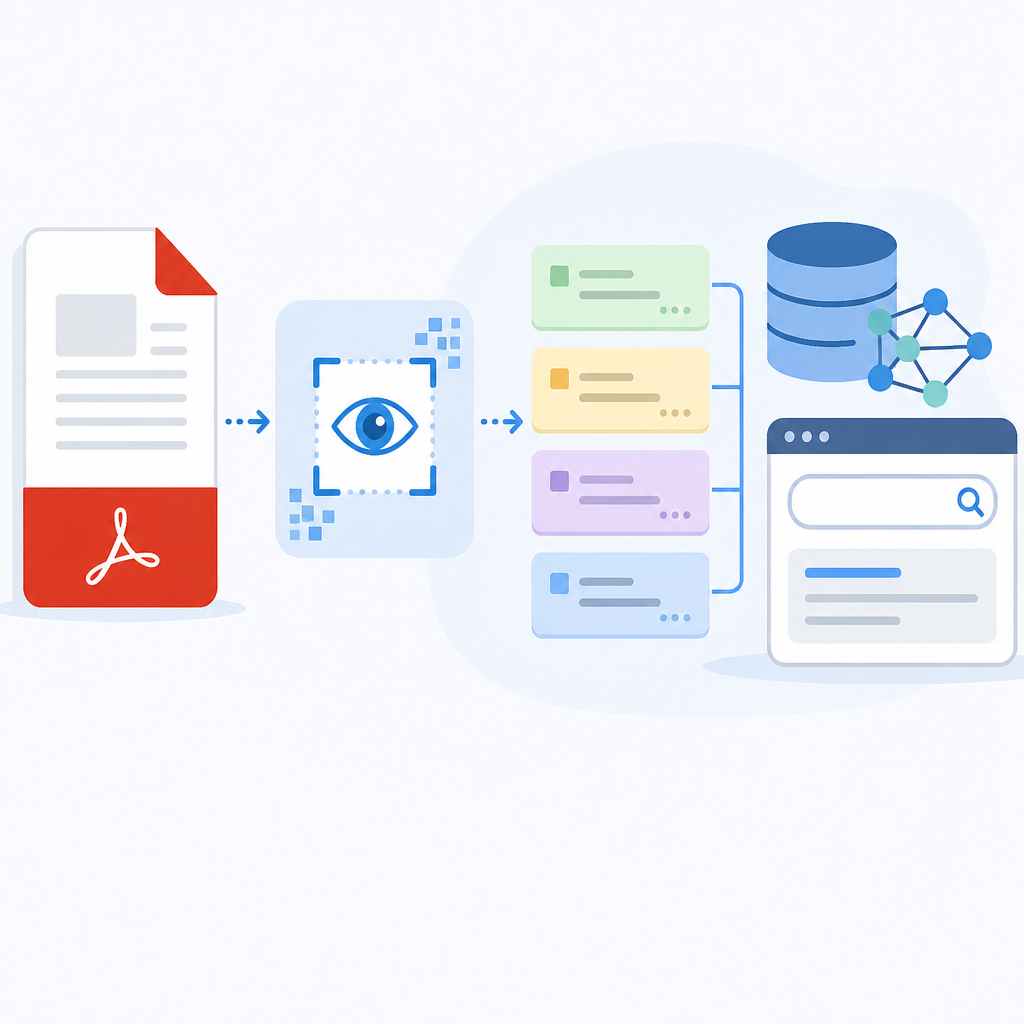
翻譯一下就是:OCR 4 想做的不是「文字擷取」,而是「文件還原」。它要保留頁面結構,讓文字、圖片、表格照著原本的順序出現,而不是把整份 PDF 壓成一串平面字串。這差很多,真的差很多。因為 RAG 最怕的不是沒資料,是資料被你自己先弄亂。
我以前做內部搜尋時踩過這個雷。掃描版政策文件看起來都正常,直到有人問一個需要同時看表格標頭和下面備註的問題。系統答得很自信,但內容完全對不上。不是 LLM 笨,是我前面的 extraction layer 已經先把文件肢解了。
實操上,我現在會先問三件事:閱讀順序有沒有保住、表格有沒有被拆碎、圖片和文字是不是還在同一個上下文裡。如果沒有,先不要談 embedding、不要談 rerank、也不要急著怪 prompt。你拿碎片給模型,它只能幫你編故事。
- 先檢查輸出是否保留 page order,而不是只看文字量。
- 表格、註解、圖說要當成結構單位,不是附屬雜訊。
- 抽樣測試一定要包含掃描件、雙欄版面、混合圖文頁。
Bounding box 不是花活,是你跟使用者交代得過去的證據
AI Business 文章提到 OCR 4 有 bounding boxes,能把文字定位、標示、畫框,讓你知道抽出的內容到底在原始文件哪裡。這聽起來很工程、很無聊,但我跟你說,真正上線後,這種無聊功能最值錢。因為使用者不想聽你講「模型說的」,他要的是「哪一頁、哪一塊、哪一行」。
也就是說,bounding box 做的不是視覺裝飾,是可追溯性。你如果在合約、法遵、政策文件裡回答問題,沒有 source region,所謂 citation 很容易退化成「檔名 + 頁碼」這種半吊子東西。能看見來源位置,才有辦法讓人信,也才有辦法人工複核。
我以前很愛偷懶,只存 chunk text 跟 page number。結果到最後 review UI 做不出來,因為使用者點了引用,只能跳到頁面,不能直接高亮那段證據。這種體驗很煩,煩到人會懷疑你到底有沒有真的做文件系統。後來我才學乖:沒有 bbox,就不要嘴硬說自己有 citation。
實操寫法很簡單:每個 chunk 至少存四個欄位,text、page、bbox、source_uri。然後 UI 要能直接跳到那個區塊,不是只顯示一段摘要。你甚至可以把 bbox 當成審核流程的核心資料,讓法務或營運直接看到答案是從哪裡抄出來的。
- 保留 bbox 的同時,也保留原始 PDF 或影像連結。
- 讓引用可以點擊、定位、highlight,而不是只有文字片段。
- 把 source provenance 當成資料模型的一部分,不是額外備註。
RAG 如果不懂版面,常常只是比較會亂講
文章裡說 OCR 4 是為了 retrieval-augmented generation 設計的。這句我認同。因為 RAG 的上限,常常不是 LLM 多強,而是你餵進去的 chunk 有多像原始文件。你如果先把版面弄壞,再把壞資料丟去做向量檢索,那後面再怎麼調參,也只是把錯誤包裝得比較漂亮。
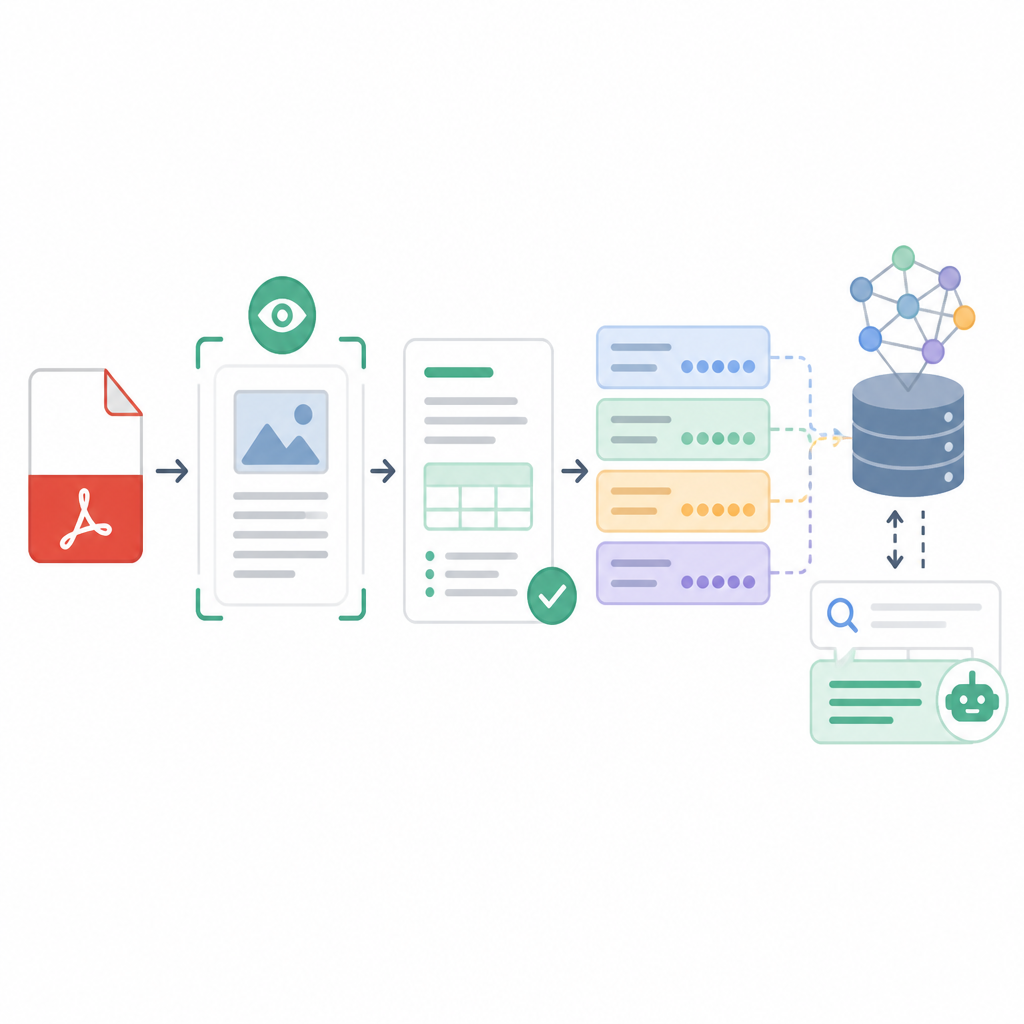
翻譯一下就是:OCR 4 真正的價值,不是「能抽字」,而是它讓文件可以被檢索系統理解。它把文字、圖片、表格按原本順序交出來,等於幫你把 chunk 的品質拉回正軌。對企業文件來說,這超重要,因為資訊常常散在標題、表格、註解、圖說裡,少一塊就會歪掉。
我看過太多團隊把心力花在 embedding model、reranker、prompt template,結果問題根本出在 chunking。表格標頭被切掉、圖說不見了、腳註獨立成一塊,retriever 當然抓不到真正有用的上下文。這不是模型問題,是你前處理把文件拆成垃圾。
實操上,我會把流程切成四層:先抽取、再以語意區塊切 chunk、再索引、最後才回答。chunk 不要用純 token 數硬切,尤其表格和圖說要黏在一起。還有一個我很堅持的事:如果 chunk 沒有 provenance,就不要讓它進 RAG。沒有證據鏈的答案,後面一定會出事。
如果你現在用 LangChain 或 LlamaIndex,我會直接講白一點:loader 比 prompt 更重要。prompt 寫得再漂亮,前面的文件抽取如果爛,最後還是會得到一個很會講幹話的系統。
多語言支援不是加分項,是企業文件的基本盤
Mistral 說 OCR 4 支援 170 種語言、10 個語言群組。這數字我不會拿來當行銷話術看,我會把它當作產品定位。因為真實世界的企業文件從來不是單語系,尤其是跨國團隊、採購、法務、客服、技術手冊,常常一頁裡就混兩三種語言。
也就是說,這不是「順便支援一下」,而是你要不要真的面對企業資料混亂現況的問題。只要 OCR 一碰到非拉丁字母、重音符號、雙語表單就爛掉,那你做的不是 enterprise tool,你做的是 demo tool。demo tool 很好看,但上線後會很吵。
我之前看過一個很慘的 rollout。前期在單一區域測試都很順,結果一進到另一個辦公室,文件語言混雜、掃描品質又差,整條 pipeline 直接爆掉。最後救火的方法也沒什麼神秘,就是重新挑 extraction、重新驗證語言處理、重新做資料品質檢查。很無聊,但有效。
實操寫法:不要只拿乾淨英文 PDF 測。你要把真實會進來的東西都丟進去,包含旋轉頁、低解析掃描、雙語頁、印章、手寫註記。你如果要做跨區域部署,最好一開始就把各地文件樣本都納進 benchmark,不然等正式上線才發現不行,會很痛。
如果你要拿它跟 Google Document AI 或 Azure AI Document Intelligence 比,我建議不要只看準確率。你要看的是輸出能不能直接拿去做搜尋、引用、審核。那才是你真正要付錢買的東西。
速度很漂亮,但管線適配才是你每天會碰到的事
文章提到 OCR 4 在單一 GPU 上每分鐘可處理最多 2000 頁,還能透過 API 和 Mistral Studio 使用。這數字很吸睛,我承認。但我做過幾輪系統後,現在看到吞吐量數字只會先冷靜一下,因為快不等於好用。你前面快,後面慢,整體還是卡。
翻譯一下就是:Mistral 想把 OCR 4 同時做成批次處理和即時服務都能用的工具。這方向沒問題。大量歸檔時,速度可以省成本;做助理時,速度可以降延遲。但真正麻煩的通常不是 OCR 本身,而是後面那些補破網的工作:重試、格式修復、頁序修正、壞 chunk 清理。
我以前有個系統,OCR 本身跑得飛快,結果最耗錢的是後處理。因為輸出格式不穩,工程師花一堆時間在 normalize、reconcile、repair。你看起來像在優化模型,其實是在幫垃圾資料打補丁。這種事做久了會很煩,因為你會發現瓶頸根本不在你以為的地方。
實操上,我現在只看端到端 latency,不看單點 runtime。要把 file ingestion、OCR、chunking、embedding、indexing、retrieval、answer generation 全部算進去。只要 OCR 4 讓抽取快了,但把 cleanup 工作變更多,那就不算贏。
文章也提到價格:API 是每 1000 頁 4 美元,Mistral Studio 的 Document AI 是每 1000 頁 5 美元。這種資訊很實用,因為你終於能拿來做 build vs buy 的粗估,不用只是憑感覺吵架。
開源搜尋能不能用,取決於文件層有沒有老實
文章說 OCR 4 整合進 Mistral Search toolkit,這是 public preview 的開源可組合搜尋框架。這點我會特別注意,因為很多團隊做文件助理時,都是先有搜尋,再硬塞 OCR,最後整套東西的 citation 對不起來,答案也對不起來。
也就是說,Mistral 想把 extraction 和 retrieval 綁得更緊。這是對的。你如果只把 OCR 當前處理,後面的搜尋層就很容易退化成「看起來很像智慧搜尋的 keyword index」。有些團隊會把這種東西包裝得很漂亮,但一問 citation 就露餡。
我其實滿喜歡 composable 系統,但前提是每一層的 contract 要清楚。chunk 是什麼、page 怎麼對應、bbox 怎麼回跳、圖片和表格怎麼表示,這些要先定義好。你如果不先定義,之後就會在 Slack 裡面花三天吵「為什麼答案有引用但找不到原文」。
實操寫法:先把 OCR 和 retrieval 的資料契約寫下來,然後整條 pipeline 都照這個契約走。不要今天 loader 這樣、明天 index 那樣、後天 UI 又自己發明一套。文件系統最怕的不是複雜,是每一層都自以為聰明。
如果你要看更完整的官方脈絡,也可以一起對照 Mistral AI 的產品頁。我的習慣是 vendor docs 跟媒體報導一起看,因為前者常少講麻煩事,後者常幫你把工程細節拉回來。
可抄的模板
# OCR 4 風格的 RAG 文件管線模板(可直接改成你的專案版)
## 目標
把掃描 PDF、圖片、混合版面文件,轉成可引用、可檢索、可審核的 RAG 輸入。
## 輸入
- PDF / 圖片 / 掃描文件
- 可選 metadata:source_system、document_id、language、owner、access_level
## 抽取規則
1. 保留閱讀順序。
2. 文字、表格、公式、圖片要照文件原始順序輸出。
3. 每個 extracted span 都要有 page number。
4. 每個 extracted span 都要有 bounding box。
5. 保留原始檔案參照,方便稽核與 review。
## 建議輸出 schema
{
"document_id": "string",
"page": 1,
"block_id": "string",
"block_type": "text|table|equation|image|caption",
"text": "string",
"language": "string",
"bbox": {"x1": 0, "y1": 0, "x2": 0, "y2": 0},
"source_uri": "string",
"confidence": 0.0
}
## Chunk 規則
- 以語意區塊切 chunk,不要只看 token 數。
- 表格列要跟表頭綁在一起。
- 圖說要跟圖綁在一起。
- 腳註不要脫離原始來源。
- 每個 chunk 都要帶 provenance:page、bbox、source_uri。
## Retrieval 規則
- 先用語意相似度找候選。
- 再用 page proximity 與 block_type 做 rerank。
- 優先回傳有 source provenance 的 chunk。
- citation 要能點回原始頁面區塊,不要只顯示 snippet。
## 回答規則
- 只能根據 retrieved chunks 回答。
- 盡量直接引用原文 span。
- 如果答案依賴表格或圖片,就顯示對應高亮區域。
- 如果證據不夠,直接說不夠,不要硬掰。
## 驗證清單
- [ ] 閱讀順序有保住
- [ ] 表格沒有被拆爛
- [ ] 混合語言頁面可處理
- [ ] bounding boxes 有存
- [ ] citation 可回到 source region
- [ ] 在髒掃描件上測過
- [ ] 端到端 latency 有量
## 給 assistant 的實用提示詞
你正在根據抽取後的文件回答問題。
只能使用提供的 chunks。
每個事實都要附 page 與 source region。
如果證據不完整,請明講缺了什麼。
不要自己補附近文字沒講的內容。
## 範例 chunk
{
"document_id": "policy-2026-04",
"page": 12,
"block_id": "p12-b3",
"block_type": "table",
"text": "Retention period: 7 years; Exceptions: legal hold",
"language": "en",
"bbox": {"x1": 112, "y1": 404, "x2": 1450, "y2": 612},
"source_uri": "s3://docs/policy-2026-04.pdf",
"confidence": 0.97
}這段我會真的拿去改。它不花俏,但它逼你養成對的習慣:保留結構、保留來源、讓 citation 看得見。這才是 OCR 4 這類工具真正有價值的地方,不是單純「抽得更快」而已。
如果是我明天要上線,我會先挑一批很髒的文件、一個明確的搜尋場景、再加一個 review UI。先別急著把整套系統做滿,先把文件弄老實。文件一旦老實,答案才有機會老實。剩下那些優化,慢慢來就好。
來源我主要拆的是 AI Business 這篇報導,裡面的引用與產品資訊是原始素材;上面這套模板和實作建議則是我根據這些資訊整理出來的衍生版本。