Reroute 讓視覺 token 可回流
Reroute 把視覺 token 從「刪掉就沒了」改成「先延後、後面還能回來」,讓 VLM 在降 token 時更保留後段推理需要的圖像細節。

Reroute 把視覺 token 從「刪掉就沒了」改成「先延後、後面還能回來」,讓 VLM 在降 token 時更保留後段推理需要的圖像細節。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:摘要無公開 benchmark 數字
- 突破點:可回收路由
Vision-language model 一直有個老問題:圖片一進模型,就常被切成很多 visual tokens。token 越多,decoder attention 和 KV-cache 的成本就越高。這篇論文要解的,不是「要不要壓縮」,而是「壓縮時能不能不要一刀切」。
作者認為,傳統做法太像先判死刑。很多 visual-token reduction 方法會先算分數,保留高分 token,低分 token 直接刪掉。但在多模態推理裡,早期看起來不重要的 token,到了後面可能才變成關鍵。尤其是需要對齊圖片局部資訊的問題,太早刪掉就回不來了。
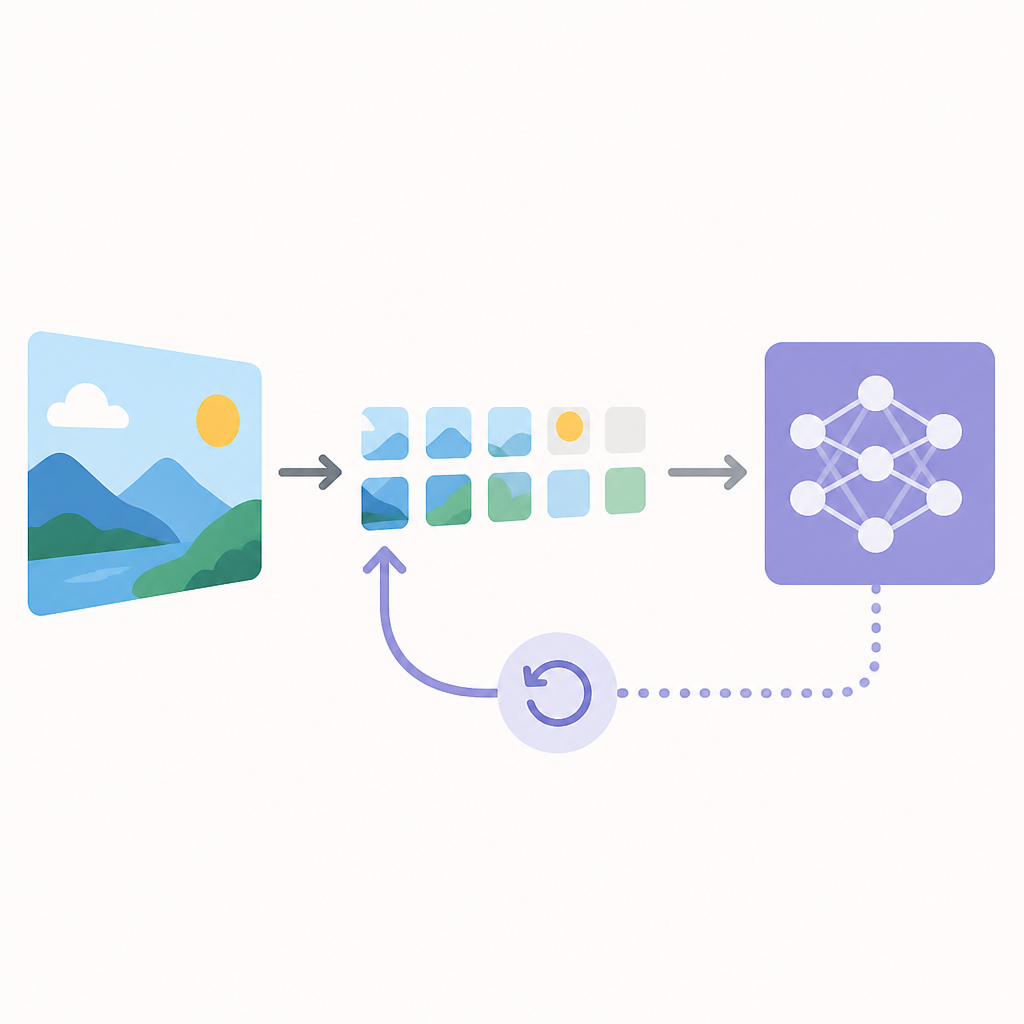
Reroute 的核心概念很直接:不要永久丟棄 token,先把它延後,讓它有機會在後面的路由決策裡再被看見。這讓 token reduction 從「一次性刪除」變成「可恢復的流動」。
這篇在修哪個痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
在 vision-language model 裡,圖片不是一路以像素形式進到 decoder。它會先被投影成一串 visual tokens,然後跟文字 token 一起參與 attention。這種設計很靈活,但代價也很明確:token 數量一多,推理就更慢、更吃記憶體。
所以很多系統都會想辦法減 token。問題在於,現有方法多半是「排序、保留、刪除」這種單向流程。這種流程假設 token 的重要性在整個 decoder 裡都差不多穩定,但論文認為這個假設不可靠。
作者的觀點是,token 的重要性會隨著 decoder 深度改變。某個 token 在前面幾層看起來不突出,不代表後面不會用到。對 grounding 敏感的任務尤其如此,模型可能在後段才需要把語言和圖片某個小區域連起來。
如果你太早把那個 token 刪掉,模型就少了一次把它撿回來的機會。這也是這篇論文真正想修的地方:不是單純壓縮,而是避免壓縮變成不可逆損失。
Reroute 到底怎麼做
Reroute 是一個 training-free 的 plug-in。意思是,它不需要重新訓練 base model。它做的是改變 decoding 時的 routing 行為,直接接在現有 pruning 方法上。
論文保留了原本常見的 attention-score ranking 和 stage-wise schedule。也就是說,它不是把整套 token reduction 推翻重寫,而是沿用既有規則,只改 token 被淘汰後的命運。
在一般 pruning 裡,沒被選中的 token 會直接消失。Reroute 不這樣做。它把這些 token 先 defer 掉,讓它們跳過當前 decoder stage,然後在下一次 routing decision 時重新進入候選池。
這個設計的重點是 recoverable。token 就算這一輪沒過,也不代表永遠出局。它還能在後面的層級被重新考慮。換句話說,Reroute 把 token reduction 變成一連串決策,而不是一次性刪除。
因為它沿用原本的 ranking 和 schedule,論文的設計目標是盡量維持原 pruning 方法的效率區間。摘要沒有給出精確的額外開銷數字,所以只能保守地說:它是想在不改變效率等級的前提下,提升 token reduction 的穩定性。
論文實際證明了什麼
摘要提到,作者把 Reroute 放到 FastV、PDrop 和 Nüwa 這些變體上測試,並且搭配 LLaVA-1.5 與 Qwen backbones。這代表它不是只對單一模型或單一 pruning 方案有效,而是試圖證明這個想法有一定通用性。
結果上,摘要說 Reroute 在 aggressive token reduction 下能改善 grounding,同時維持一般 VQA 表現。這裡要注意,摘要沒有公開完整 benchmark 數字,所以不能從這份材料直接讀出提升幅度,也不能拿它去對照特定分數。
但方向很清楚。當問題需要模型回頭利用圖片中的局部細節時,recoverable routing 比硬刪除更有彈性。它不是讓模型「更會看圖」這麼空泛,而是讓模型在 token 被降載後,還保留重新取用的機會。
這也說明一件事:token reduction 本身不是錯,錯的是把「低分 token」直接等同於「永遠沒用」。論文的訊息比較像是在提醒工程實作:你不一定要改 ranking model,先改 token 的處置流程,就可能得到更好的行為。
對開發者有什麼實際影響
如果你在做多模態產品,visual-token reduction 幾乎就是少數幾個能直接動到 latency 和 memory 的槓桿。decoder 要同時看很多 image tokens,成本很快就上來。這時候,任何降 token 的方法都很誘人。
但問題也很現實:降得太兇,模型可能在一般問答看起來還行,遇到需要對圖像細節做 grounding 的任務就掉下去。這篇論文的價值,在於它提供了一個更保守、也更工程化的折衷:先降載,但不要把後路封死。
Reroute 的另一個優點是 training-free。這對實務很重要。你不用重訓整個 VLM stack,就能把它當成一個 plug-in 疊到現有 pruning 方法上試試看。對團隊來說,導入門檻比重新設計整套 token reduction pipeline 低很多。
它也提醒開發者,multimodal efficiency 不只是「少一點 token」而已,而是 token 的生命週期怎麼管理。某些 token 不是全局重要,但在 decoder 的某個深度、某個時機點會變重要。可回收路由就是把這個假設寫進系統裡。
這篇的限制也很明顯
先講最直接的:摘要沒有公開完整 benchmark 數字。沒有表格、沒有 latency、沒有 memory 的精確數值,也沒有失敗案例。就算方向看起來不錯,光靠這份摘要還不能量化它到底贏多少。
第二個限制是泛化範圍。摘要確實提到它在 FastV、PDrop、Nüwa,以及 LLaVA-1.5 和 Qwen 上測試,但沒有說不同 decoder depth、不同 routing schedule,或更極端 token budget 下會怎麼表現。這些都會影響你能不能直接拿去上線。
第三個問題是系統細節。token 如果被 defer 好幾次,最後什麼時候才算真的沒用了?摘要沒有交代停止條件,也沒有說重新放回候選池會不會帶來額外成本。對 production 來說,這些細節都很關鍵。
不過,這篇論文的主張其實很務實:如果你一定要減少視覺 token,那就不要把第一次排序當成最後判決。先降載,再保留回流空間,這樣模型比較不容易把後段需要的圖像資訊一起丟掉。
總結
Reroute 的重點不是把 pruning 推翻,而是把它變得沒那麼不可逆。它用可回收路由,讓被暫時跳過的 visual tokens 還能在後面重新進場,特別適合那些需要 grounding 的多模態任務。
對開發者來說,這是一個很實用的設計方向:效率還是要顧,但 token 不一定要一刪到底。這篇論文證明的,就是這個折衷有機會比傳統硬刪更穩。
- Reroute 把不可逆刪除改成可回收路由。
- 它是 training-free,可疊加在既有 pruning 方法上。
- 摘要只說改善 grounding 與維持 VQA,沒有公開完整 benchmark 數字。