TurboQuant 讓長上下文推理更省記憶體
5 項重點看懂 TurboQuant 如何在不重訓下壓縮 KV cache,將記憶體用量最多降 6×,並在長上下文推理中提升吞吐。

TurboQuant 在推理時壓縮 KV cache,讓長上下文 LLM 更省記憶體,也更容易提速。
讀完這 5 項,你可以判斷 TurboQuant 是否比傳統權重量化更適合你的部署場景,尤其是當 GPU 記憶體先卡住、而不是模型檔案太大時。
| 項目 | 規格 A | 規格 B | 規格 C |
|---|---|---|---|
| TurboQuant | KV cache | 最多 6× 省記憶體 | 最多 8× attention 加速 |
| 權重量化 | 模型權重 | 縮小模型檔案 | 對 KV cache 幫助有限 |
| 長上下文服務 | 注意力記憶體壓力 | 多數情境約 2× 吞吐提升 | 更容易受 cache 影響 |
| 3–4 bit KV cache | 精度 | 檢索基準近乎無損 | 適合長文本任務 |
1. 推理時壓縮 KV cache
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
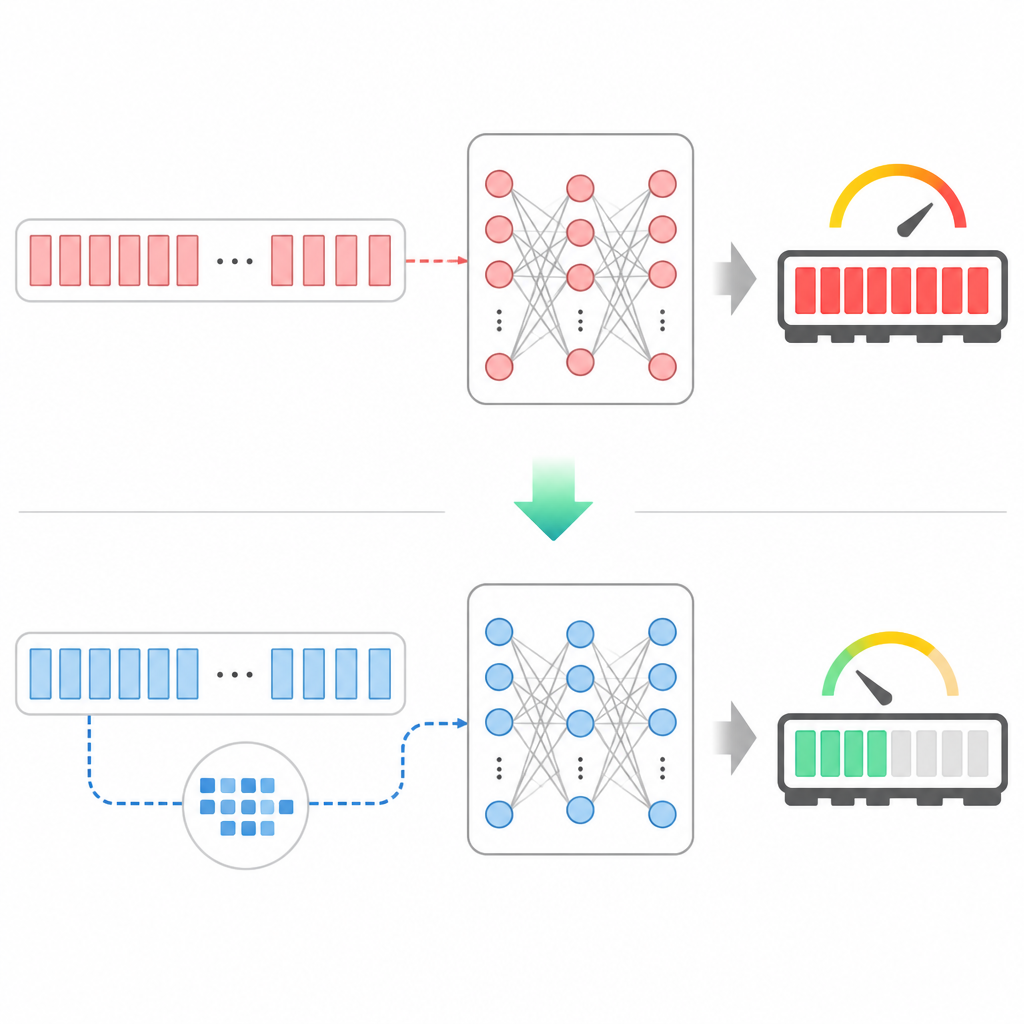
TurboQuant 直接處理生成過程中成長最快的 KV cache,而不是只縮模型權重。這讓它在模型本體不變的情況下,也能降低推理時的記憶體壓力。

當 prompt 很長、或同時服務很多使用者時,瓶頸常常不是算力,而是 cache 佔掉的 GPU 記憶體。TurboQuant 的做法是減少 attention 需要搬運與保留的資料量。
- 針對 autoregressive decoding 產生的 key 和 value
- 不需要重訓,也不需要校準資料
- 可接到既有 transformer serving 架構
2. 先整理,再低位元存放
它在推理時採兩步驟:先對 KV activation 做 per-channel 與 per-token normalization,再把 cache 以低位元整數格式存起來,常見是 4-bit 或更低。
這個前處理步驟是準確率能守住的關鍵。先把分布整理得更容易壓縮,再在 attention 需要時即時解碼,才能同時兼顧記憶體與品質。
1. Normalize KV activations
2. Store in 4-bit or lower integer format
3. Decode during attention
4. Use the compressed cache for weighted sums3. 長上下文吞吐更高
TurboQuant 最有感的地方,是上下文長度把記憶體頻寬推到上限的場景。原始素材提到,在 H100 GPU 上 attention 最快可到 8×,多數長上下文情境吞吐也可提升約 2×。
這不只是更快,也代表尾延遲更穩。當 cache 變小,同一張 GPU 能同時容納更多請求,對聊天機器人、copilot 和批次推理都很直接。
- 長文件問答
- 多使用者聊天服務
- 大 prompt 批次推理
4. 3–4 bit 仍可維持接近無損
TurboQuant 受到關注的原因之一,是它沒有明顯以品質換速度。素材指出,在 LongBench、Needle-in-a-Haystack 這類檢索基準上,3–4 bit 的結果可接近無損,甚至零損失。
不過,低位元仍可能在敏感領域帶來小幅退化。這代表它很適合一般檢索與長上下文任務,但上線前仍應用自己的 prompts、輸出與失敗案例做驗證。
- 適合:檢索型基準
- 適合:長上下文助理
- 需測試:高風險或專業領域任務
5. 更容易下放到本地與邊緣裝置
因為 KV cache 需求降低,TurboQuant 也讓較大的模型更有機會跑在筆電、手機或本地推理盒上。素材提到,若記憶體可降到 6×,一些原本只能上雲的工作負載,可能開始進入消費級硬體範圍。
這會改變成本與產品設計。本地推理能提升隱私、降低網路延遲,也少掉按次計費的雲端成本,對想做雙部署路線的團隊特別有吸引力。
- 重視隱私的企業應用
- 離線或低連線助理
- AI PC 與記憶體較充裕的行動裝置
哪種適合你
如果你的痛點是長上下文把記憶體吃滿,而不是模型檔案太大,TurboQuant 會比傳統權重量化更對症。它特別適合想在不重訓的前提下提升推理效率,而且能接受低位元帶來的小幅風險的團隊。
如果你主要想縮小模型檔案或加快載入速度,權重量化通常就夠了;但如果你要在同一套硬體上服務更多 tokens、更多使用者,或更長的 prompt,TurboQuant 的切入點更直接。