為什麼 Tether 把本地 AI 記憶推進日常裝置是對的
TurboQuant 的價值不在於更快,而在於把長上下文 AI 從資料中心拉回手機、筆電與邊緣裝置,讓本地 AI 真正可用。

TurboQuant 把長上下文 AI 變成本地裝置可用的功能,不再只靠資料中心。
Tether 把 TurboQuant 放進 QVAC SDK 是對的,因為真正卡住實用 AI 的不是模型話題,而是記憶體。當一段對話拉長到幾十輪,KV cache 會快速膨脹,最後把助理、寫程式工具、文件分析器逼回雲端。Tether 自己給的例子很直接:一個 4B 模型在約 262,000 tokens 時,光是 cache 就可能吃掉約 8 GB 記憶體;四個這樣的 session,還沒算模型本體,就可能逼近 32 GB。這不是邊角問題,而是許多「本地 AI」一旦開始有用,就立刻不再本地的原因。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
本地 AI 失敗,常常不是算力不夠,而是記憶體先爆。手機、筆電、邊緣盒子通常能跑起一個模型,但不一定撐得住長對話、長文件或整個 codebase 的上下文。KV cache 若隨 session 長度線性成長,每多一頁內容、每多一輪追問,都是部署成本。把 cache 壓縮最高 5 倍,不是小修小補,而是把「能 demo」和「能上線」分開。

這點在真實工作場景最明顯。法律審閱、研究整理、事故排查、教學輔助、私密筆記分析,這些任務都不是單次 prompt,而是長鏈條互動。上下文就是產品本身,模型太早忘記,使用者拿到的只是反覆重置的按鈕。Tether 把記憶壓縮當成基礎設施是對的,因為本地 AI 不會靠每次都換更大的 GPU 來擴張;它要靠更好的記憶管理,才有機會進入日常使用。
第二個論點
TurboQuant 的價值不只在演算法,而在於它被做成開源、可移植的工程路徑。研究成果常常死在論文裡,原因很簡單:團隊要自己重寫、調參、再把它塞進雜亂的推理堆疊。Tether 把量化流程、適配器、文件與工作負載配置一起提供,等於把一個研究主張變成開發者能在消費級 GPU、手機晶片、邊緣設備上驗證的工具。
可移植性才是戰略勝點。如果這種能力只存在於單一封閉 API 裡,只會加深對中心化雲端的依賴。相反地,開源實作能給新創與獨立開發者一個共同底座,去做離線助理、隱私敏感工具與去中心化應用。它也降低試驗成本:小團隊不必先買進超大規模部署模型,才能開始做長上下文功能。生態系就是這樣長出來的,不靠口號,而靠能在普通硬體上跑起來的程式碼。
反方可能怎麼說
最強的反對意見是,壓縮總會有代價。即使 TurboQuant 能把品質損失壓到很低,它仍然是在一個本來就帶有隨機性的系統上再加一層近似。企業在意的是可重現性、可稽核性和最壞情況行為,不只是平均 benchmark 分數。從這個角度看,雲端仍然更穩,因為它提供更簡單的運維、集中監控與容量規劃;如果供應商能在託管環境裡保證大上下文窗口,何必把另一層優化壓到客戶端?
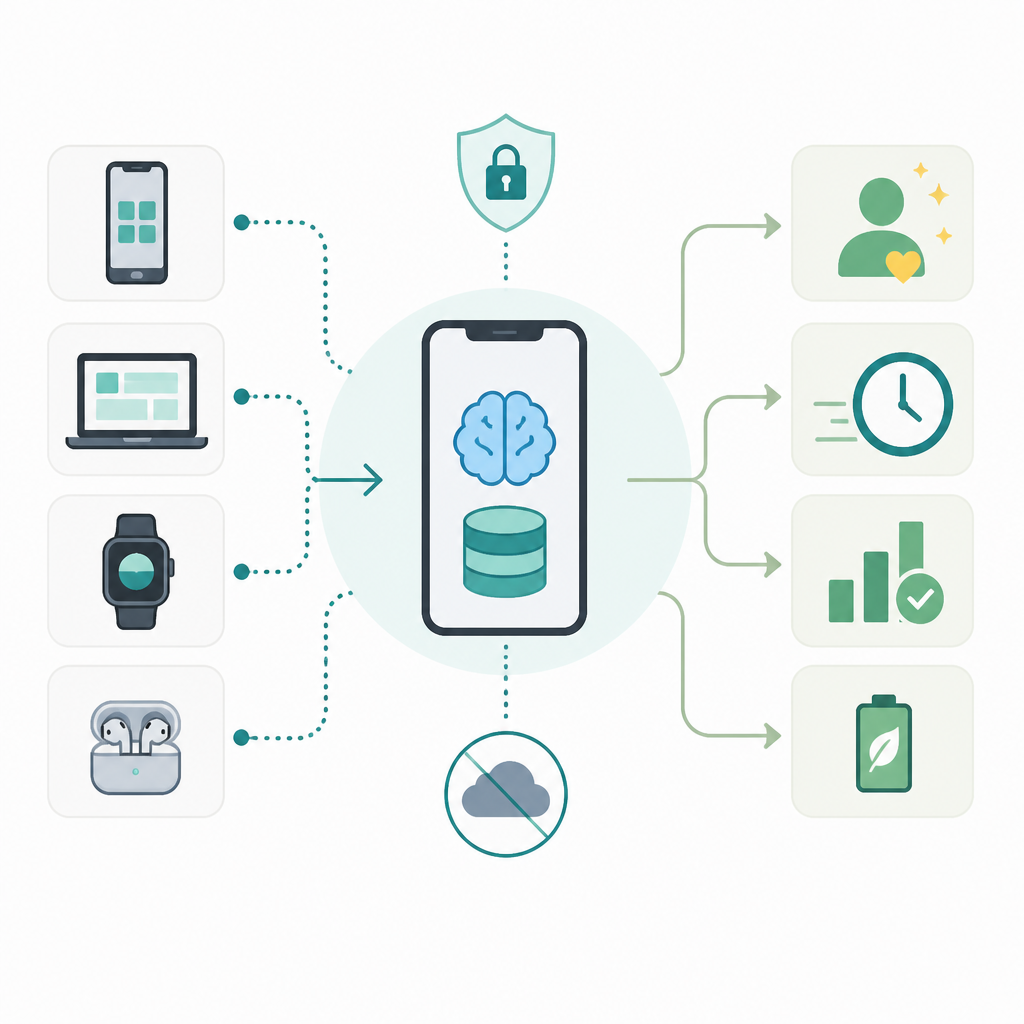
這個質疑成立,但它只劃出邊界,沒有推翻方向。雲端 AI 仍然必要,尤其是最大規模工作負載、重訓練任務與最嚴格的企業部署。但這不改變一件事:日常 AI 使用中,有很大一部分就是被裝置端記憶體卡住。對這些任務來說,選項不是完美的本地 AI 對上完美的雲端 AI,而是可用的本地 AI 對上根本做不到的本地 AI。TurboQuant 擴大了前者,這就足夠重要。
你能做什麼
工程師應該停止用短 prompt 思維設計本地 AI,改把記憶體當成第一級產品約束。若你在做助理、寫程式工具或文件工作流,就拿長 session、大檔案與真實裝置限制去測,找出 KV cache 是在哪裡打爆體驗。PM 應該把成功定義成上下文保留、離線連續性與隱私工作負載,而不只是 token 吞吐。創辦人則可以把 TurboQuant 這類能力當成分發策略:把功能送到使用者所在的裝置,能留在本機的資料就留在本機,只有真正需要時才上雲。