TurboVec cuts 10M-vector RAM to 4GB
TurboVec compresses 10M vectors from 31GB to 4GB and removes training from vector search.

TurboVec compresses 10 million vectors to 4 GB and skips quantizer training.
TurboVec matters because it changes the cost math for vector search: a 10 million document index that can take about 31 GB in FAISS IndexFlatL2 can shrink to about 4 GB with TurboQuant, without a training pass.
1. TurboQuant’s data-oblivious compression
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core idea behind TurboVec is TurboQuant, a quantizer from Google Research and New York University that does not need sample data to build a codebook. Instead of learning from your corpus, it uses math about high-dimensional vectors to set the compression scheme ahead of time.

That makes the index easier to deploy when your data changes often. You can add new vectors, switch embedding models, or rebuild from scratch without first collecting a training set for the quantizer.
- Published at ICLR 2026 as arXiv:2504.19874
- Uses normalization, random rotation, and Lloyd-Max scalar quantization
- Works with 2-bit and 4-bit settings
2. The Rust index with Python access
TurboVec is the production implementation of TurboQuant. It is written in Rust, exposes Python bindings, and is meant to slot into real retrieval pipelines rather than stay as a paper-only method.
For teams that already use Python for embeddings and orchestration, that matters. You can keep your application code in Python while using a faster, smaller index layer underneath. The project also supports stable IDs and deletes through an IdMapIndex wrapper.
- Install with
pip install turbovecorcargo add turbovec - Supports
TurboQuantIndexandIdMapIndex - Can persist indexes to disk and load them later
3. Memory savings that change deployment options
The headline benchmark is simple: 10 million vectors at 1,536 dimensions can move from 31 GB in a common FAISS setup to about 4 GB in TurboVec at 4-bit quantization. That is the difference between needing a heavy server and fitting into much smaller infrastructure.
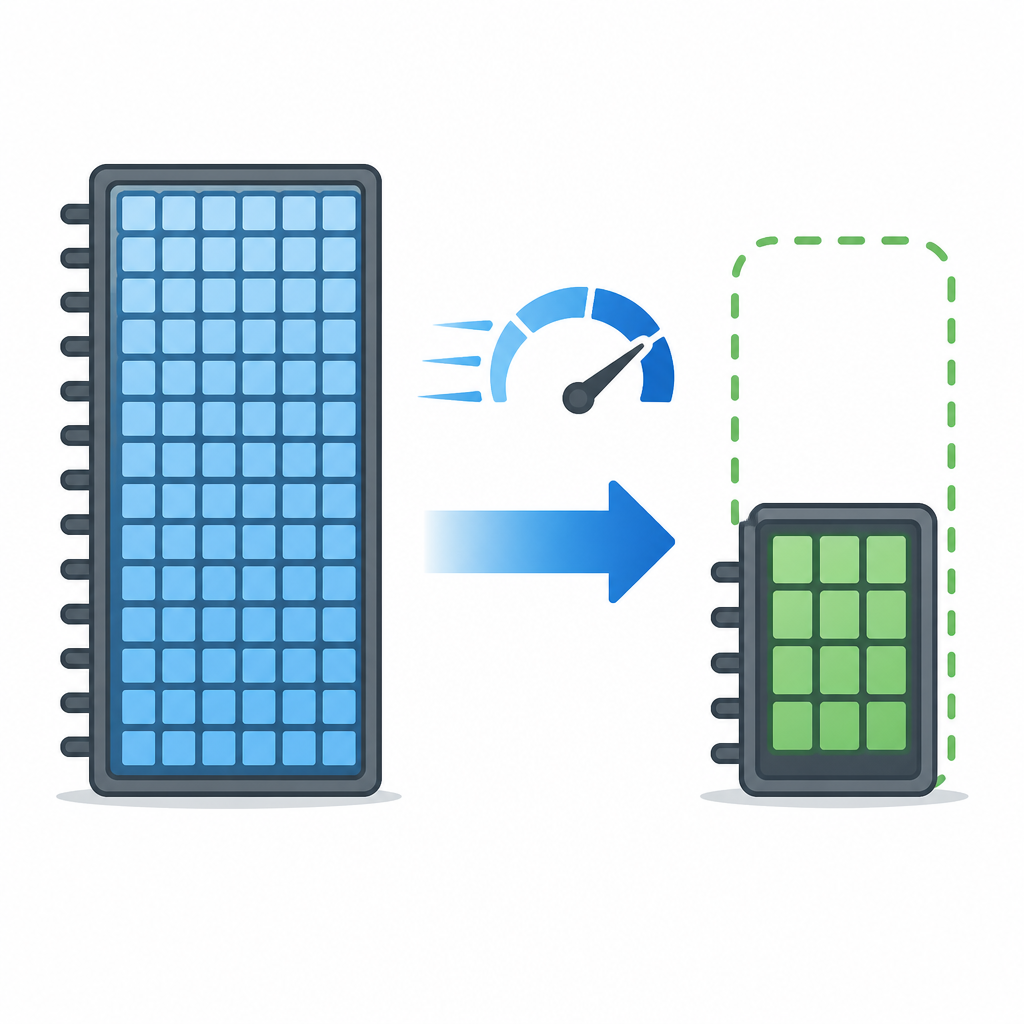
TurboVec also offers a 2-bit mode for even tighter storage. In the article’s comparison, that gets the same 10 million-vector index down to about 2 GB. The result is more room for local search, cheaper cloud instances, and less pressure on cache and memory bandwidth.
| Item | Memory for 10M vectors | Compression vs raw float32 |
|---|---|---|
| Float32 raw | 61.4 GB | 1x |
| FAISS IndexPQFastScan (4-bit) | ~7.7 GB | ~8x |
| TurboVec (4-bit) | ~4.0 GB | ~15x |
| TurboVec (2-bit) | ~2.0 GB | ~30x |
4. Search without a training step
Traditional product quantization needs a training phase before indexing. TurboVec removes that step, which simplifies incremental updates and reduces the pain of changing embeddings later. For live systems, that can matter more than a small gain in theoretical elegance.
The code path is also straightforward. You create the index, add vectors, and search. There is no offline clustering job, no codebook rebuild, and no warmup period for a new corpus.
from turbovec import TurboQuantIndex
index = TurboQuantIndex(dim=1536, bit_width=4)
index.add(vectors)
scores, indices = index.search(query, k=10)5. Framework fit for RAG teams
TurboVec is not just for benchmark charts. It integrates with common retrieval stacks, including LangChain, LlamaIndex, and Haystack, which makes it easier to test inside existing RAG systems.
If you are already using one of those frameworks, the main benefit is practical: you can try a smaller index without rewriting the rest of the pipeline. That lowers the cost of evaluating whether memory savings outweigh any retrieval tradeoffs in your own workload.
- LangChain integration via
TurboVecVectorStore - LlamaIndex and Haystack support available through package extras
- Rust and Python APIs share the same core index model
How to decide
Pick TurboVec if your pain point is memory, deployment cost, or the overhead of retraining a quantizer every time your embeddings change. It is especially attractive for large RAG systems, local search, and teams that want a smaller operational footprint.
Stick with a more traditional FAISS setup if your current index is already affordable and your team values a mature ecosystem over a newer compression method. TurboVec is strongest when index size and update simplicity matter as much as raw retrieval speed.
// Related Articles
- [IND]
Cloudflare Is Too Expensive to Buy After the Surge
- [IND]
Midjourney V8.1 now ships as default model
- [IND]
Midjourney Free Methods vs Paid Access
- [IND]
Anthropic’s $35 billion buildout proves AI now runs on finance and ch…
- [IND]
OpenAI Partner Network widens enterprise AI access
- [IND]
AI Weekly: 2026-06-08 ~ 2026-06-15