Vector Lakebase is Zilliz’s bid to collapse the AI data stack
Zilliz Vector Lakebase argues that vector search, discovery, and batch analytics should run on one data foundation.

Zilliz Vector Lakebase combines vector search, discovery, and batch analytics on one shared data foundation.
Zilliz is making the right bet: AI infrastructure should stop splitting serving, exploration, and analytics into separate systems, and Vector Lakebase is a serious attempt to unify them. The company is not just adding another retrieval feature to Milvus. It is packaging production vector search, lake-native storage, and on-demand compute into one platform, which is the direction the market is already moving as teams try to reduce copy-heavy pipelines and the operational drag of parallel stacks.
The first argument: AI teams are paying too much for data duplication
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core problem is not search quality, it is data movement. Zilliz says teams often move billions of vectors between serving and batch systems, and that process can take days. That is the real tax on modern AI infrastructure: every duplicate index, every synced copy, and every separate compute layer adds delay and cost before a model ever learns from feedback.

Vector Lakebase attacks that tax with a zero-copy semantic data plane on shared lake-native storage. Zilliz claims a single logical copy of the data can support real-time serving, interactive discovery, and batch analytics from gigabytes to petabytes. That is a meaningful architectural shift because it treats vectors as a living dataset, not a static artifact that must be exported, re-ingested, and reindexed for each workload.
The second argument: the economics are better than the serverless default
Zilliz is also making a cost argument that matters to buyers. In its internal benchmark on one billion 768-dimensional vectors with 10 hours of monthly active compute, On-Demand Search cost $318 versus $4,937 for a comparable serverless path. That is not a rounding error. It is the difference between a platform team approving experimentation and forcing the product group to ration queries.
The pricing logic is strong because many AI workloads are bursty. Discovery sessions, semantic deduplication jobs, and training-data prep do not need always-on infrastructure. By billing compute only when it is active, Zilliz is aligning cost with usage instead of charging for idle time. That matters for startups, but it matters even more for enterprises that want to run more retrieval and analytics without multiplying cluster spend.
The third argument: unified search is becoming the default requirement
Vector Lakebase is not just about storage economics. It also folds dense vectors, sparse vectors, text, JSON, geospatial data, BM25, regex, multi-vector search, and reranking into one system. That is the right product shape for AI applications that no longer use retrieval as a single lookup step. They need hybrid search, iterative search, and multi-path retrieval inside the same workflow.
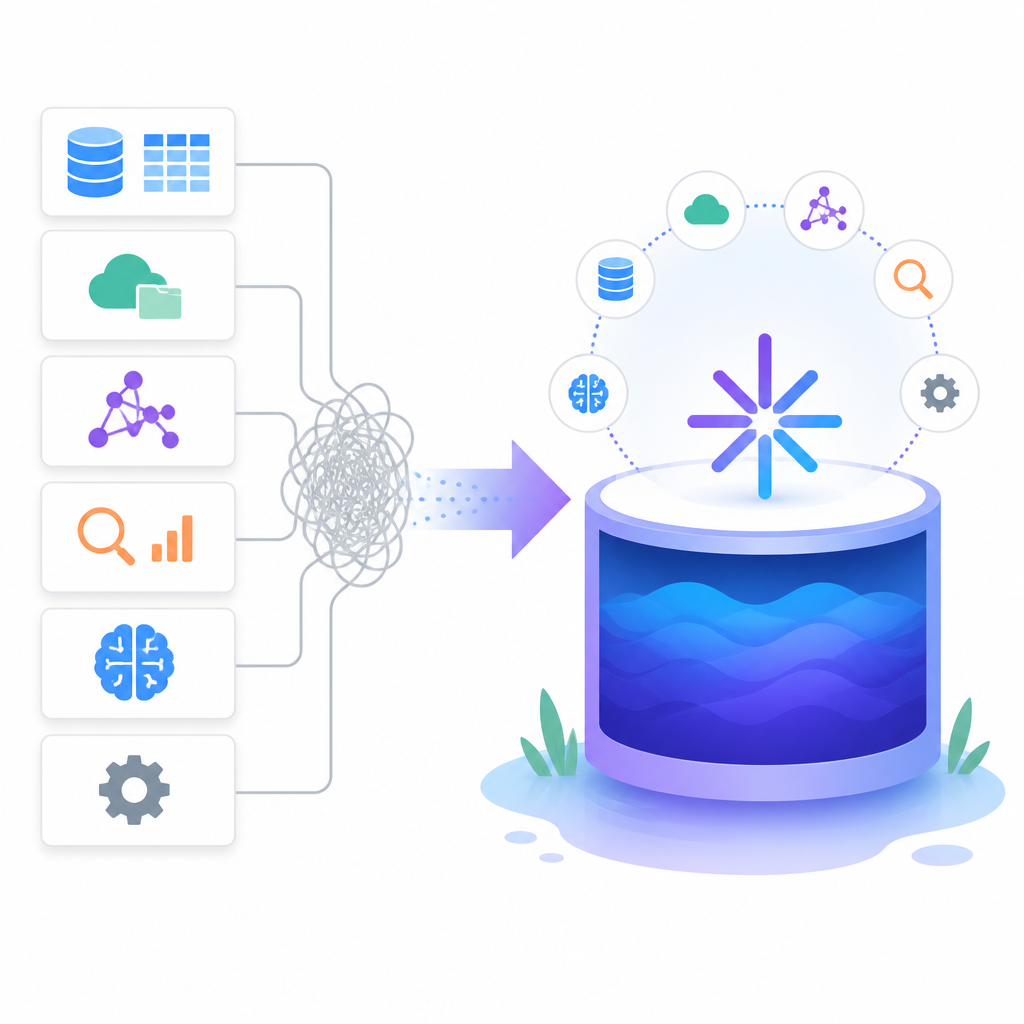
This is where Zilliz has a real advantage. The company already sits inside production search for thousands of teams, and it names customers like Zillow, OpenEvidence, Exa, Filevine, and MiniMax. If those teams are already depending on Milvus or Zilliz Cloud for low-latency retrieval, adding discovery and analytics on the same foundation removes a whole class of integration work. The platform becomes more valuable because it reduces the number of places where data can drift.
The counter-argument
The strongest objection is that unified platforms often become compromise machines. Serving wants low latency, analytics wants flexibility, and lake storage wants cheap scale. Put those together and you risk getting a system that is elegant on slides but awkward in production, especially for teams with extreme performance needs or custom pipelines that already work.
There is also a real vendor-lock-in concern. A single logical data foundation is convenient until the team wants to move part of the stack elsewhere. If one platform owns storage, indexes, compute orchestration, and search semantics, switching costs rise fast. That makes some architects prefer a best-of-breed stack, even if it is messier.
That critique is valid, but it does not defeat Zilliz’s move. The company is not asking teams to abandon production search performance; it is keeping real-time vector search at the core and layering new workloads around it. The lock-in concern is also weaker when the alternative is already a patchwork of separate systems, custom sync jobs, and duplicated indexes. In practice, most teams are not choosing between purity and lock-in. They are choosing between one coherent platform and a brittle pile of tools that already locks them in through operational complexity.
What to do with this
If you are an engineer or PM building retrieval-heavy AI systems, use this launch as a signal to audit your stack: count how many copies of the same vectors you maintain, how much time you spend syncing them, and which workloads are still trapped on separate systems. If your team is spending real effort moving data between serving, discovery, and analytics, the case for a unified data platform is no longer theoretical. If you are a founder, design for the loop now, not just the query, because the companies that win will be the ones that can serve, learn, and re-serve without rebuilding the pipeline each time.
// Related Articles
- [IND]
Kimi K3 pushes open-weight AI toward default
- [IND]
Anthropic’s open-model fight reveals its lonely AI stance
- [IND]
Immich Docker Compose setup that avoids common errors
- [IND]
Millions Raised for Zhipu-style Social World Model
- [IND]
Anthropic’s Book Scanning Strategy Could Set a Pattern
- [IND]
Huang’s open-letter playbook for open-weight AI