LeVo 2 用分層建模做完整歌曲生成
LeVo 2 透過分層表示與漸進式後訓練,改善完整歌曲生成的穩定性、可控性與音樂性。

LeVo 2 透過分層表示與漸進式後訓練,改善完整歌曲生成的穩定性、可控性與音樂性。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:六個主觀維度
- 突破點:混合 token 規劃加平行細化
完整歌曲生成一直不好做。模型不只要生出像樣的旋律,還要顧到長時間的結構一致性、歌詞對齊、主唱與伴奏分離,以及最後輸出的音訊品質。這篇論文把 LeVo 2: Stable and Melodious Song Generation via Hierarchical Representation Modeling and Progressive Post-Training 放在這個問題上,主張用分層表示與漸進式後訓練,來減少「全局規劃」和「局部細節」之間的拉扯。
對開發者來說,這篇最有意思的地方,不是它能不能唱,而是它怎麼拆解任務。作者沒有把所有責任丟給單一表示,而是把歌曲生成切成幾個階段:先做語意規劃,再做 track 細化,最後重建波形。這種設計很像工程上的模組化思維,重點是讓不同層次各做各的事。
它想解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要直接點出現有語言模型式歌曲系統的一個結構性矛盾。混合 token 建模有助於讓人聲和樂器協調,但容易把屬於不同 track 的細節弄糊。雙軌預測雖然能保留較好的聲學細節,卻會把序列拉長,也可能削弱全局規劃能力。簡單講,現有系統常常是在「結構」和「細節」之間二選一。

這個問題之所以麻煩,是因為完整歌曲不是短音檔。模型要在更長的時間尺度上保持穩定,還要讓歌詞和音樂對得上,不能生成到一半就開始漂移,最後聽起來像拼接出來的片段。論文把 LeVo 2 定位成一個 hybrid LLM-diffusion framework,就是想把這些約束一起處理,而不是把它們塞進同一個單體預測目標裡。
摘要沒有公開完整 benchmark 細節,所以目前能確定的是方法論方向,而不是某個單一分數。文中提到系統有做專家聆聽測試和客觀評估,但沒有在摘要裡列出具體指標數字。
方法怎麼運作
LeVo 2 的核心是 hierarchical modeling。第一段由語言模型 LeLM 負責,先預測混合 token,做出歌曲的語意規劃。這一步像是先畫出整首歌的藍圖,先決定大方向,再往下做細節。
接著系統不是直接收尾,而是再平行預測人聲與伴奏 token,讓每個 track 都能做更具體的修正。這代表模型不是只靠一條單一路徑往前推,而是把全局與局部拆開處理。對生成式音訊來說,這種分工有助於同時保住整體結構和局部聲學細節。
最後,系統用 diffusion-based Music Codec 把 token 重建成完整波形。也就是說,流程不是「生 token 然後直接播放」,而是先規劃、再細化、最後重建音訊訊號。作者想保的是兩件事:高層次的音樂結構,以及低層次的聲學品質。
這篇延伸版工作還多了一個很關鍵的訓練安排:aesthetics-guided training schedule。預訓練階段會用自動化的 music aesthetic evaluation framework,替大規模資料分配 musicality-tier 條件。白話一點,就是先把資料按音樂性分層,讓模型先吃到帶有音樂性先驗的資料,再進入偏好對齊。
這種做法很像先建立基礎規則,再開始做精修。作者不是一開始就直接衝 preference optimization,而是先讓模型從有層級標註的資料中學習,再做 progressive post-training。摘要列出的三個階段是 supervised fine-tuning、large-scale offline DPO,以及 closed-loop semi-online DPO。作者的說法是,這三步分別改善生成品質、可控性和音樂性。
論文實際證明了什麼
摘要的結果描述是:expert listening tests 和 objective evaluations 顯示,LeVo 2 在六個主觀維度上都優於 open-source baselines。它也說系統在幾個聆聽指標上接近領先的商業系統。這代表作者想傳達的是,模型不只在技術上有拆解能力,感知品質也有提升。
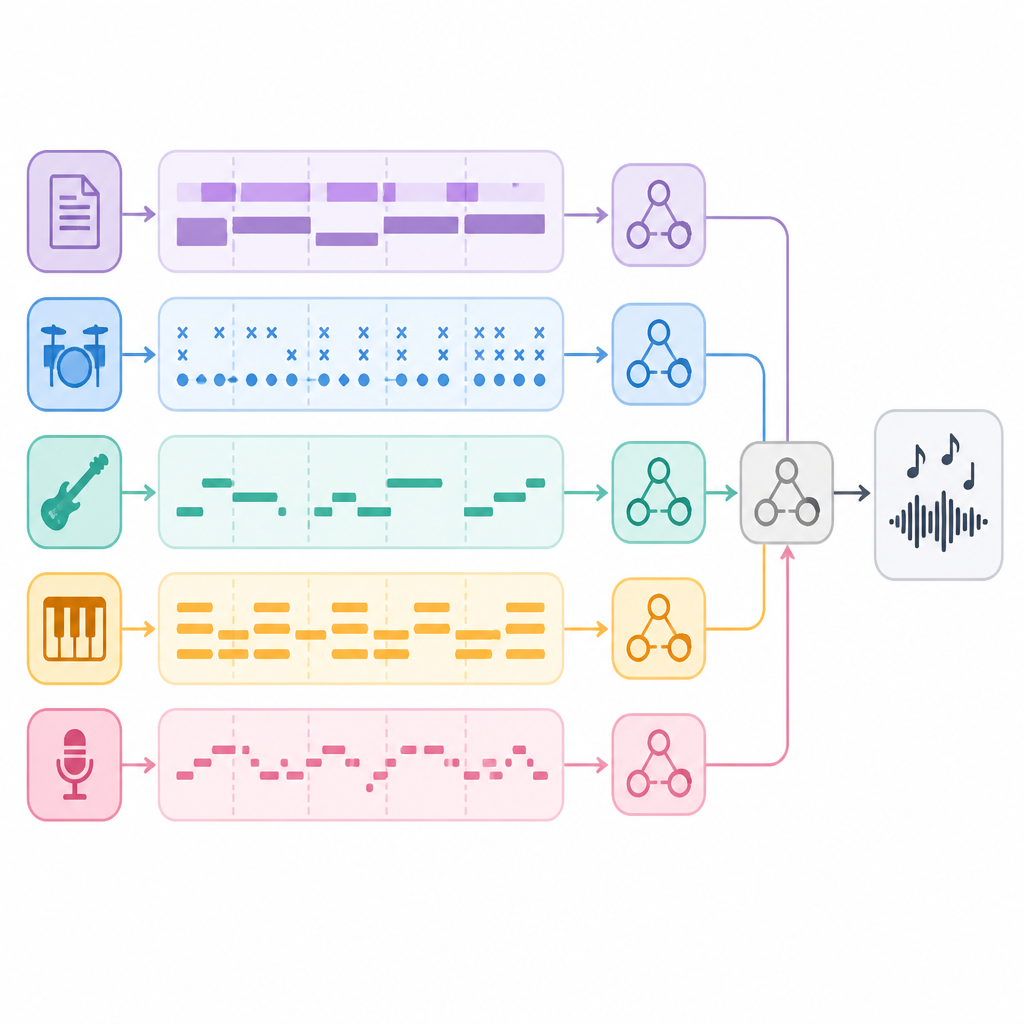
但這裡要先踩煞車。摘要沒有提供實際分數、baseline 名稱,也沒有列出那些聆聽指標到底是什麼。換句話說,你可以從摘要知道它「看起來更好」,卻還不能只靠這段文字判斷提升幅度有多大。對實作團隊來說,這比較像一篇方法與訓練策略都很完整的研究,而不是摘要裡已經把 benchmark 全部攤開的報告。
摘要還提到有做 ablation,而且這些 ablation 驗證了訓練策略、aesthetics guidance、scale,以及 hierarchical architecture 的效果。這表示作者不是只靠單一技巧撐結果,而是想證明整個系統的不同部件都有貢獻。
如果把這件事翻成工程語言,就是:不是某個神奇 token 一次解決所有問題,而是表示法、訓練流程、偏好對齊和重建器一起協作,才把完整歌曲的品質拉上來。
為什麼這個訓練流程重要
這篇最有辨識度的地方,可能是 progressive post-training。摘要的論點很明確:把 musicality learning、controllability alignment 和 acoustic refinement 分開處理,可以減少優化衝突。白話一點,就是不要逼同一個階段同時扛所有目標,因為這些目標彼此會打架。
這也是為什麼作者把 offline DPO 和 semi-online DPO 當成分段的偏好對齊工具,而不是一次性的修補手段。摘要的 framing 是,靜態的 offline preference pairs 有侷限,尤其在歌曲生成這種多維度任務上更明顯。加上 closed-loop semi-online 之後,模型可以在初始 supervised 階段後繼續修正行為。
另外還有一個 modular extension step,會訓練 Track-Specific LM 來做 acoustic refinement,同時保留已對齊的 semantic planner。這點很值得注意,因為它反映出作者想維持全局規劃的穩定性,同時改善局部音質。對做生成式系統的人來說,這是很典型的工程問題:後面的微調不要把前面學到的能力洗掉。
開發者可以怎麼看
如果你在做生成式音訊,LeVo 2 的價值在於它把歌曲生成視為一個分層系統問題。某個階段負責規劃,某個階段負責 track 細節,某個階段負責波形重建。這種拆法理論上會比單一端到端堆疊更容易除錯、調參,也更容易擴充。
這篇也提醒一件事:在多模態生成裡,訓練策略的重要性已經不亞於模型架構。摘要裡真正被強調的,不只是 LeLM 或 diffusion codec,而是資料條件化、偏好對齊、分階段後訓練這整套流程。對創作型生成任務來說,訓練管線本身可能就是產品效果的一半。
但限制也很清楚。摘要沒有交代資料集大小、benchmark 名稱、聆聽測試流程,也沒有說拿來比較的商業系統是哪些。它也沒有告訴我們這條 hybrid LLM-diffusion pipeline 的訓練成本或推理成本。對任何想重現或導入的人來說,這些都是一定會想先知道的實務問題。
所以最短的結論是:LeVo 2 想靠分層規劃、track 細化和波形重建,把完整歌曲生成做得更穩,再用漸進式後訓練把品質、可控性和音樂性一起拉高。摘要給的訊號是正面的,但細節還不足以讓人完整審核數字。
這篇研究的實際影響
如果這個方向成立,後續做音樂生成的團隊可能會更常把任務拆成多階段,而不是硬把所有目標塞進同一個 token 空間。這對系統設計很重要,因為它讓「全局一致」和「局部細節」不再是互相排斥的選項,而是可以在不同模組裡分別優化的目標。
另一個影響是,偏好對齊不一定要只做一次。這篇把 offline DPO、semi-online DPO 和 supervised fine-tuning 串成一條流程,等於在說:對於像歌曲這種高維度創作任務,訓練順序本身就是模型能力的一部分。
總之,LeVo 2 不是只在講「生成得像不像」,而是在處理「怎麼讓一首完整歌在長時間尺度上保持穩定」。對研究者來說,這是架構與訓練策略的組合題;對開發者來說,這是如何把生成系統拆得更可控的實戰題。
- 分層建模把全局規劃和 track 細化拆開,降低互相干擾。
- 漸進式後訓練把 SFT、offline DPO、semi-online DPO 串成流程。
- 摘要有正向結果,但沒有公開完整 benchmark 數字與測試細節。