為什麼 2026 年 prompt engineering 錯了
2026 年真正決定 AI 輸出品質的不是 prompt 技巧,而是 context engineering;結構化輸入、範例與工具串接,才是降低錯誤與提升可重複性的關鍵。

2026 年決定 AI 輸出品質的,不是 prompt 技巧,而是 context engineering。
Prompt engineering 已經不是區分好壞輸出的主技能;context engineering 才是。研究與實務都在指向同一件事:當你把角色、任務、格式、範例、限制與工具輸入設計好,模型表現會明顯穩定。相反地,靠一句「幫我寫得好一點」去碰運氣,通常只會得到不可重複的結果。
第一個論點:結構比即興更重要
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
語言模型不是照人類直覺推理,而是根據你給的上下文預測下一個 token。這代表 prompt 不是咒語,而是規格書。當你明確定義角色、任務、輸出格式、受眾與限制,你不是在修飾指令,而是在消除歧義;歧義,才是錯誤輸出的主要來源。

最簡單的框架已經證明這點。像 RTF、TAG、TASS 這類方法之所以有效,是因為它們迫使使用者先做決策,再交給模型執行。一句「你是運動營養師,請產出 7 天菜單,並以 HTML 表格輸出」不只是比隨口要求更清楚,它也更便宜、更容易重現,而且更不容易跑題。這就是為什麼這些框架能覆蓋大多數日常場景。
第二個論點:範例比聰明措辭更有用
研究早就把答案講明白了。Brown 等人在 2020 年的 few-shot learning 工作中發現,給 GPT-3 提供 10 到 100 個範例後,它在特定任務上的表現可以逼近甚至超過微調模型。這件事打破了一個迷思:提升輸出品質的關鍵,不一定是更強的訓練,而是更好的示例。
所以 CARE 與 CREATE 這類框架才實用。CARE 的最後一個 E 是 Example,意思很直接:把抽象要求變成可模仿的模式。CREATE 更進一步,把 additions、extras、negative constraints 都納進來。實務上,「不要提競品」「避免誇大」「不要用反問開場」這些負向限制,常常比一整頁正向指令更有效。這不是吹毛求疵,而是控制。
第二個論點:複雜任務需要推理框架,不是更花俏的 prompt
一旦任務變複雜,輕量框架就不夠了。Chain-of-Thought、Tree of Thoughts、ReAct、Self-Refine 之所以存在,是因為它們逼模型把中間步驟攤開,而不是一次亂猜。數字很直接:在 Game of 24 基準上,標準 CoT 只解出 4%,Tree of Thoughts 卻拉到 74%。這不是小幅改善,而是從玩具變工具。
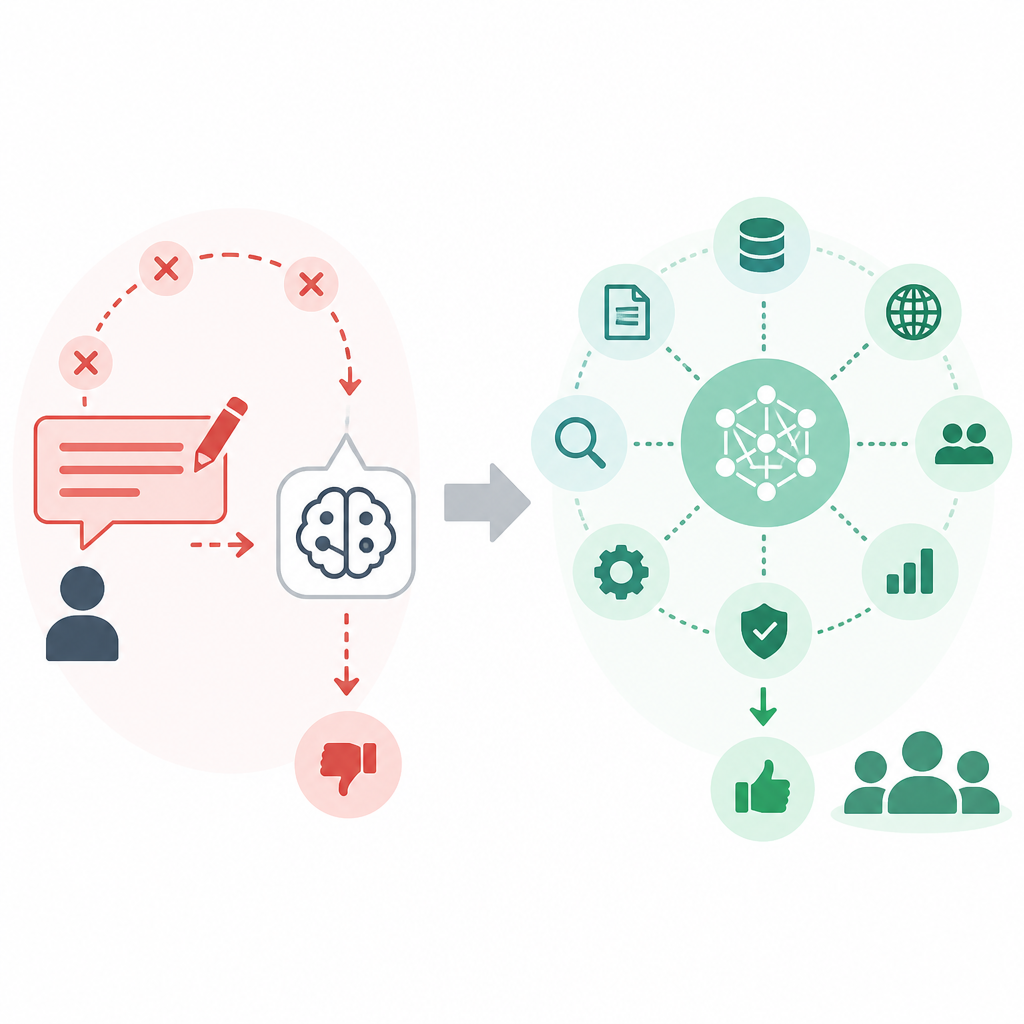
ReAct 更清楚地說明,這個領域早就超過單純 prompt 技巧。當模型要搭配搜尋、計算、驗證與外部工具時,靜態文字回答的上限很低。現在很多 agent 工作流都建立在這種模式上。若你的場景涉及檢索、工具或多步決策,prompt 只是第一層;真正決定成敗的是 context pipeline。
反方可能怎麼說
舊式 prompt engineering 最強的辯護是,它仍然是最快取得價值的方法。對行銷人來說,寫文案;對創辦人來說,整理會議紀錄;對工程師來說,產生一段程式碼,好的 RTF prompt 往往就夠用。多數人也不需要 agent stack、retrieval layer 或程序化編排。他們只需要一個乾淨的請求與穩定的格式。
這個說法並沒有錯,但只適用於一次性任務。當輸出必須可重複、可稽核、可嵌入產品時,「prompting」這個詞就太小了。context engineering 才是正確名稱,因為真正的工作是選擇輸入、範例、工具、限制、記憶與檢索,讓模型可靠地做事。Prompting 是戰術,context engineering 才是系統。
你能做什麼
如果你是工程師,別再優化花俏措辭,改為優化輸入設計:定義 schema、加入範例、加上負向限制,並在需要事實或動作時接入檢索或工具。如果你是 PM,把 prompts 當成介面來設計,並用一致性、延遲、失敗模式與使用者信任來衡量品質。如果你是創辦人,把 AI 功能建立在 context pipeline 上,而不是 prompt library 上。到了 2026 年,贏的團隊不是 prompt 模板最炫的團隊,而是最懂得提供上下文的團隊。