4 種世界動作模型,正在改寫機器人策略
4 種世界動作模型設計路線,從影片先驗到逆動力學與混合堆疊,幫你判斷機器人政策該往哪個方向投資。

世界動作模型正在成為機器人策略的第二條路,和 VLA 並行競爭。
看完這 4 種設計路線,你就能判斷:團隊該先押影片先驗、逆動力學、聯合預測,還是直接做混合式架構。這不是抽象趨勢,而是會影響資料需求、控制方式與部署難度的選擇。
| 項目 | 核心思路 | 代表訊號 | 對機器人策略的影響 |
|---|---|---|---|
| 1. 影片骨幹 WAM | 先用預訓練影片模型當 policy backbone | 強世界動態先驗 | 較容易吃進視覺變化與未來狀態 |
| 2. 逆動力學 WAM | 從狀態轉移反推動作 | 動作標註較少也能學 | 適合從影片學控制結構 |
| 3. 聯合預測模型 | 同時預測未來狀態與動作 | 感知與控制一起對齊 | 有助長時序任務與規劃 |
| 4. 混合 VLA-WAM 堆疊 | 語言理解加上世界預測 | 語意與物理一起處理 | 更接近可落地的通用策略 |
1. 影片骨幹先上場
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
WAM 最直觀的做法,是直接拿預訓練影片模型當控制骨幹,再把它微調成機器人策略。這樣做的重點不是從零學「怎麼動」,而是先借到一個對物體持續性、運動軌跡、場景變化都很熟悉的先驗。
像 NVIDIA Cosmos 這類方向,還有 DreamZero、LingBot-VA、Cortex 2.0,都在示範同一件事:影片預訓練可能比純機器人資料更省樣本。
- 常見輸入:影像、影片、語言、潛在狀態
- 常見輸出:未來幀、latent 特徵、動作片段
2. 逆動力學把問題倒過來
逆動力學的思路更像「看結果猜過程」。模型先看現在觀測與未來觀測,再反推出最可能造成這段變化的動作序列。這讓它很適合處理動作標註少、但影片資料多的場景。
如果你的資料大多來自網路影片或示範錄影,而不是大量機器人 log,這條路會特別有吸引力。它也常和離散動作 token 或 latent action space 搭配,讓模型能從狀態轉移中學到控制結構。
o_t + o_t+k -> a_t:t+k-1
3. 聯合預測把感知和控制綁在一起
聯合預測的核心,是讓同一個 policy 同時輸出未來狀態與動作。這種做法的好處很直接:模型如果要同時說明「接下來會發生什麼」與「現在該做什麼」,內部表徵就比較不容易脫鉤。
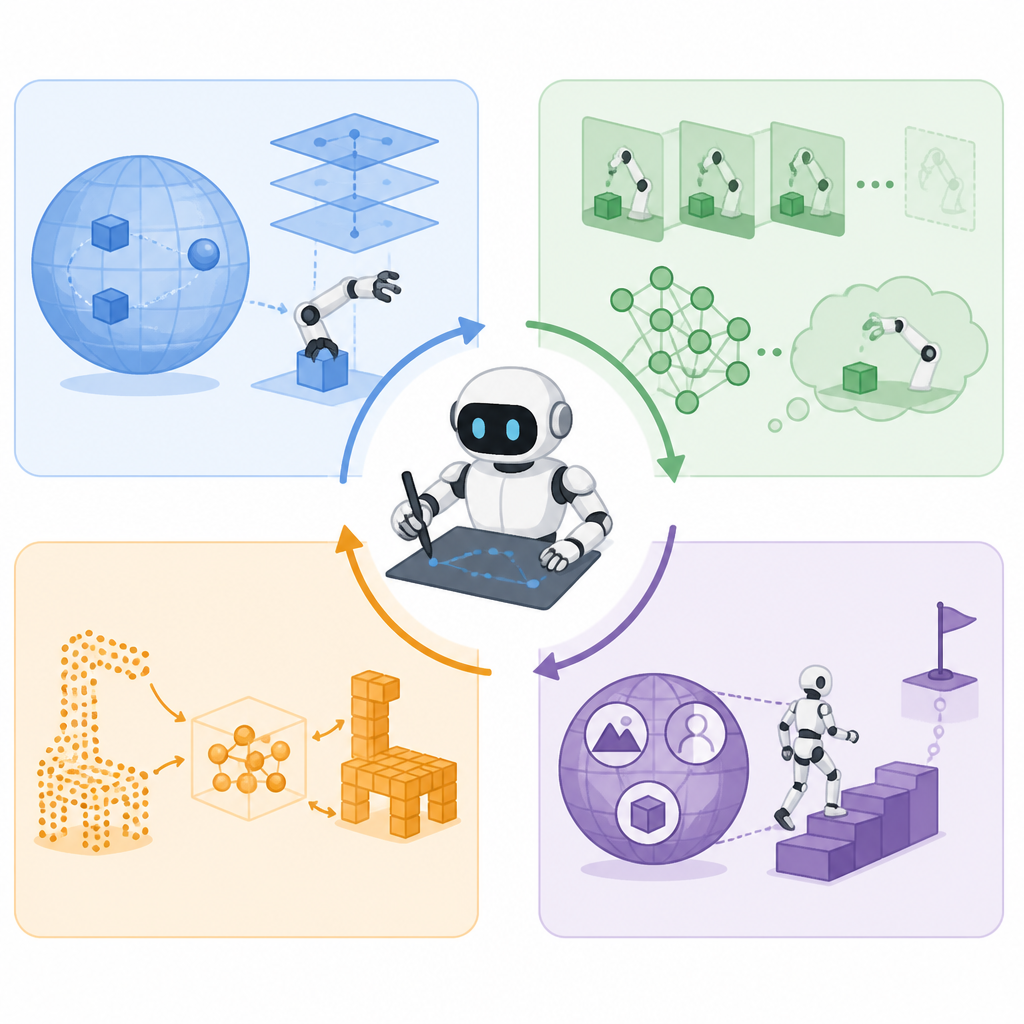
對長時序任務來說,這通常比只吐動作更穩。因為策略不只是在執行,還在持續檢查自己對環境變化的理解是否一致。
- 可用 action chunk 取代單步控制
- 可搭配 latent 預測或明確未來幀
4. 混合 VLA-WAM 最像落地解
現在最值得注意的,不一定是純 VLA 或純 WAM,而是兩者混合。做法通常是先用語言能力強的 vision-language backbone 負責指令理解,再交給 world model 去處理場景演化與動作生成。
這種堆疊很符合實際機器人需求:一邊要懂人講什麼,一邊要知道物理世界接下來會怎麼變。當任務同時牽涉語意對齊、接觸動作與分佈外情境時,混合架構往往最有工程價值。
- 適合已有 VLM 與影片基礎設施的團隊
- 適合需要指令理解加上動態預測的任務
5. 大規模預訓練正在改變門檻
WAM 之所以突然變得更像主流,不只是架構巧,而是預訓練規模開始到位。文中提到 VLA Foundry 的 Foundry-LLM checkpoint,採用 1.2B 非 embedding 參數、在 800B DCLM-Baseline-1.0 tokens 上訓練,這代表通用預訓練已經能先把底子打好。
對 WAM 來說,這個訊號很重要:機器人資料不再是唯一燃料。影片語料、世界模型目標、跨模態基座一起進來後,模型在進入真實控制前就已經有更強的先驗。
- 預訓練來源可以是文字、影片或多模態資料
- 真實機器人微調仍然必要
哪種適合你
如果你最在意的是指令跟隨、現有機器人堆疊與快速落地,VLA 仍然是保守選擇;如果你更在意場景動態、從影片學控制,影片骨幹 WAM 和逆動力學會更有吸引力。
如果你的目標是做通用策略、又不想在語言與物理之間二選一,混合 VLA-WAM 是最值得追的路線。這份清單真正要幫你做的決定,就是先分清楚瓶頸在語言、世界預測,還是兩者之間的落差。