Base 的 sequencer 當機證明單一排序器太脆弱
Base 連續停機顯示,單一 sequencer 的 L2 以便利換來的可靠性太少,已不適合被當成嚴肅的基礎設施。

Base 連續停機顯示,單一 sequencer 的 L2 以便利換來的可靠性太少。
Base 這次的連續故障,直接證明單一 sequencer 的 layer-2 設計太脆弱,不該再被包裝成可接受的工程折衷。
根據 Base 的事後報告,一個 block-building 邏輯的 bug 在無效交易失敗後留下了「stale journal state」。看起來只是局部錯誤,結果卻是全網停擺兩次:一次 116 分鐘,一次 20 分鐘。對只有一個 sequencer 的系統來說,執行狀態的一個缺陷不再是單點故障,而是整條鏈的故障。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
單一 sequencer 的問題,不在於它會出錯,而在於它出錯時沒有退路。Base 的架構無法在 sequencer 走到壞路徑時自動繞開問題,報告也寫明,sequencer 和 validator nodes 都無法跨過那個無效 block,直到修復步驟完成。這不是韌性,而是把硬依賴偽裝成擴展性。

這不是 Base 獨有的偶發事件。Base 自己的事後報告也提到,Arbitrum、OP Mainnet、zkSync Era 都出現過類似的 sequencer 相關中斷。這個案例的重點因此很清楚:問題不是某一行程式碼寫錯,而是單一 sequencer 模型本身就把 block production 的關鍵路徑壓在一個元件上。只要那個元件出現邊界情況,整條鏈就可能停下來。
第二個論點
恢復時間和根因一樣重要。Base 雖然修補了 journal-state bug,但服務不是立刻回來。團隊說,因為一些無關的基礎設施條件,緩解比預期更久,之後系統 reset 又碰上一個 race condition,進一步拖慢完整恢復。這件事真正暴露的,不只是 bug 本身,而是操作團隊在壓力下把系統拉回乾淨狀態的能力有多脆弱。
對一個據 L2beat 顯示、總鎖倉價值接近 110 億美元的網路來說,恢復機制本身就是產品的一部分。若一條鏈因為 state cleanup 和 reset 行為不穩而停兩小時,那就不是單純的 downtime,而是證明它過度依賴人工介入,以及在高壓下仍要完美執行的流程。這種設計不該被視為可接受的基礎設施。
反方可能怎麼說
支持單一 sequencer 的人會說,這是務實的折衷。它更簡單、更容易推進,也比完全分散的排序層更容易優化。再者,這類中斷是可見、可修、而且相對少見的;相比之下,更分散的設計往往要付出更高的複雜度和延遲成本。
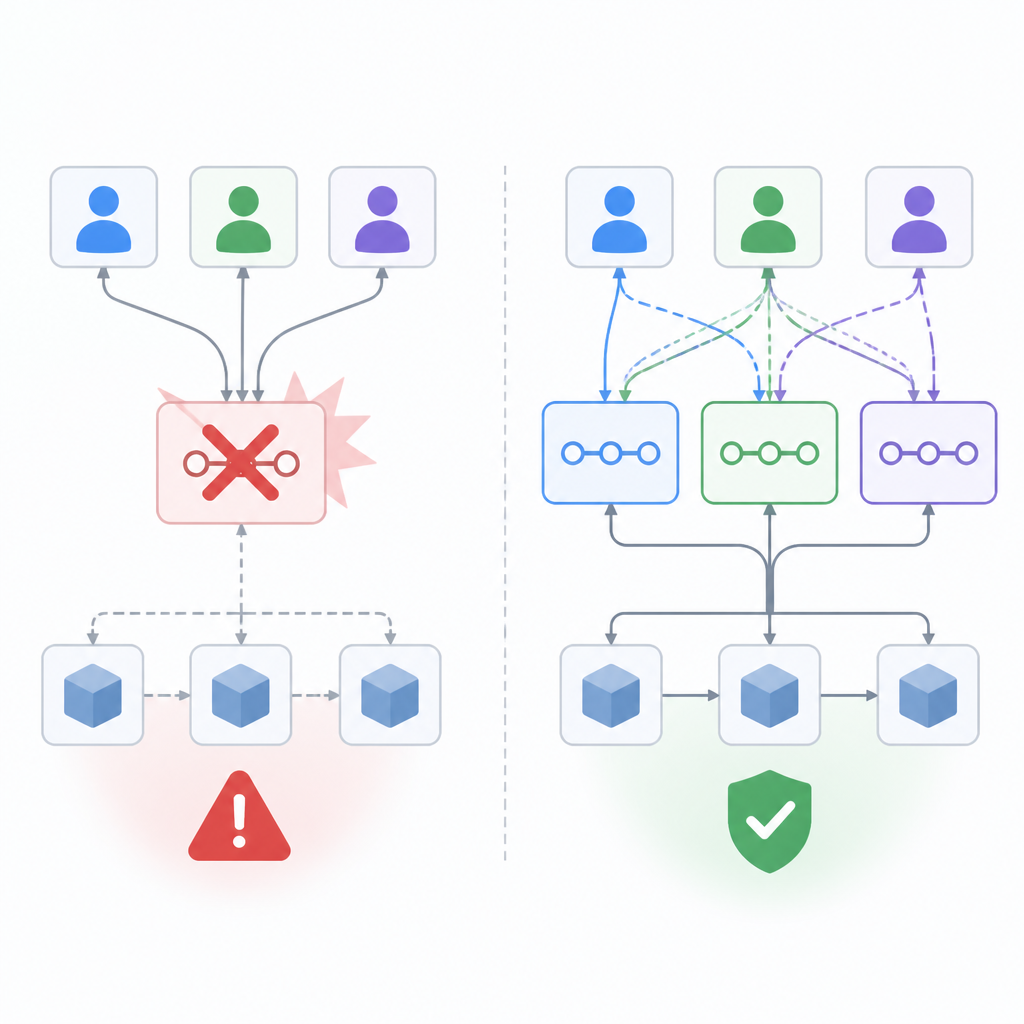
這個說法並非全無道理。早期 layer-2 的確需要迭代空間,操作簡化也能改善吞吐量與開發者體驗。單一 sequencer 可以讓 block ordering 更有效率,並在協議成熟前維持系統精簡。
但 Base 事件顯示,這個邏輯有明確邊界。簡單只有在失敗能被隔離時才是優點;這次卻是一個 bug 直接讓 block production 停了兩次,且 reset 行為與 race condition 讓恢復更慢。對已經承載大量價值與用戶活動的網路來說,這不是可以接受的代價。正確做法不是把中心化說成暫時必要,而是現在就設計可優雅失敗的機制;否則就得承認,這種架構天生不夠穩。
你能做什麼
做 L2 基礎設施的工程師,應把 fault isolation、deterministic recovery 和對執行狀態轉換的高強度 fuzz testing 放在優先級前排。PM 應把 mean time to recovery 視為核心產品指標,不是 ops 附註。創辦人則不該再把單一 sequencer 說成無害的實作細節,而要把它當成明確風險,公開設計冗餘、降級路徑與責任機制。