Google OpenRL 把 RL 細調搬上 Kubernetes
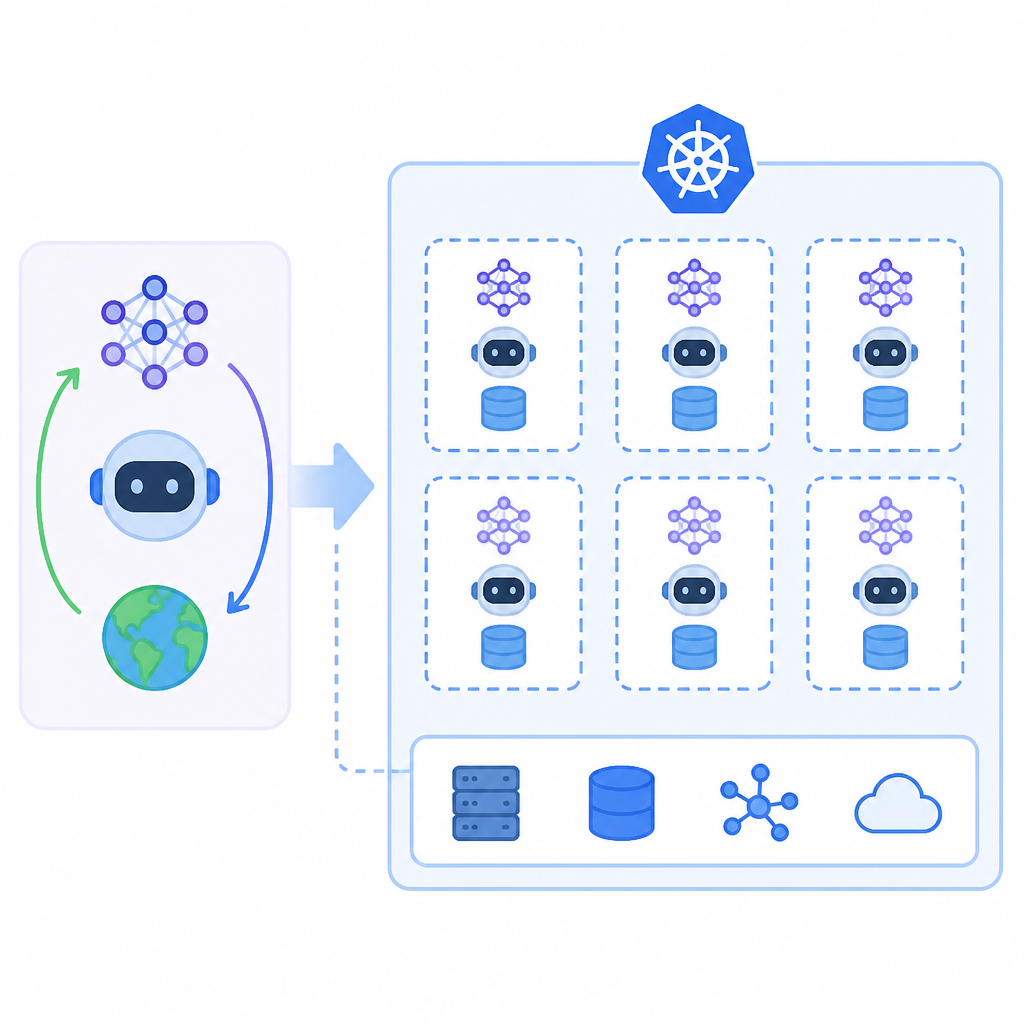
Google OpenRL 讓團隊在自己的 Kubernetes 叢集上做 LLM post-training 與 fine-tuning,重點是把研究流程和基礎架構拆開,減少 RL 迭代時的雜務。

Google OpenRL 讓團隊在自己的 Kubernetes 叢集上做 LLM post-training 與 fine-tuning,重點是把研究流程和基礎架構拆開,減少 RL 迭代時的雜務。
Google 的 OpenRL 在 2026 年 6 月 24 日釋出。它的想法很直接。把 RL 的執行層搬到一般 Kubernetes 叢集上,不要再把整套流程綁死在研究者自己的機器。
這件事聽起來很工程味,但其實很現實。LLM 的 post-training 常常卡在資料處理、reward 設計、推理除錯、硬體配置,還有叢集維運。Google 直接把這些痛點拆開,讓研究者管 recipe,平台團隊管執行。
說白了,這不是在做一個更花俏的訓練框架。它是在處理一個老問題:RL fine-tuning 一旦進到實戰,常常就變成系統整合地獄。OpenRL 想把這坨雜事壓回平台層。
| 項目 | 內容 |
|---|---|
| 釋出日期 | 2026 年 6 月 24 日 |
| 目標環境 | macOS、Nvidia GPU、GKE |
| 核心用途 | 自架 API,用於 LLM post-training 與 fine-tuning |
| 示範工作流 | Gemma 的 text-to-SQL 平行參數掃描 |
Google 為什麼要把 RL 和叢集拆開
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
OpenRL 的核心抱怨很務實。多數 RL 工具把研究邏輯和基礎架構邏輯混在一起。這會讓每次實驗都難重現,也讓擴充規模變得很煩。

Google 的做法,跟 Kubernetes 早年的思路很像。使用者只要描述要跑什麼。平台自己決定跑在哪裡、怎麼擴充、壞掉怎麼恢復。這種分工,對 AI 團隊其實很重要。
如果你做過 LLM 訓練,你大概懂那種痛。今天改一個 reward,明天要重配 GPU,後天還要查為什麼某個 worker 掛掉。OpenRL 想把這些工作從研究者手上拿走,丟給叢集去處理。
- 研究者可以專心改 reward 和資料。
- 平台團隊可以共用同一套叢集。
- GPU 不會一直閒著等 CPU 步驟跑完。
- 模型邏輯和執行邏輯終於分開了。
OpenRL 在實務上改了什麼
最直接的變化,是 GPU 利用率。Google 說,傳統 RL loop 常常是順序式流程。昂貴的加速器會卡在旁邊等其他步驟。OpenRL 讓多個 job 跑在同一套基礎設施上,能把硬體吃得更滿。
這對大模型 post-training 很有感。因為真正燒錢的,通常不是演算法本身,而是硬體時間。你每多跑一輪實驗,都是在燒預算。能平行跑,就能少浪費等待時間。
OpenRL 也附了一個 autoresearch recipe。它示範了在 Gemma 上做 text-to-SQL 的平行參數掃描和 reward 調整。這代表它不是只想做漂亮的 API,而是真的想讓團隊更快試錯。
“It is incredibly easy to get bogged down in system complexity,” Google engineers wrote in the OpenRL announcement.
這句話很準。RL for LLM 本來就夠難了。你還要自己處理叢集、排程、失敗重試、資源切分,整個流程就會變成雙倍痛苦。OpenRL 想減掉的,就是這層額外稅。
如果你把它放到台灣常見的團隊場景來看,就更好懂。很多公司不是沒有 GPU,而是 GPU 被零碎流程吃掉。有人跑 notebook,有人手動丟 job,有人還在用一台測試機硬撐。OpenRL 這類工具,就是在逼大家往共享流程走。
它和其他 post-training stack 差在哪
OpenRL 不是唯一在做這件事的專案。FeynRL 也走類似路線。它把 training recipe 和系統邏輯拆開,然後再搭配 DeepSpeed、Ray、vLLM 做擴充。
這個比較很有意思。它顯示市場不想要一個什麼都包的巨大框架。大家想要的是薄薄一層 API。研究者可以快點改,維運者也能保留控制權。講白了,就是不要把所有東西塞成一坨。
OpenRL 的定位更偏向自架和 Kubernetes。這對已經有內部平台的團隊很友善。你不用再把資料、模型和執行環境全丟給外部服務。你可以留在自己的叢集裡面跑。
- OpenRL:偏向自架 API 與 Kubernetes。
- FeynRL:偏向 recipe 和系統分離。
- DeepSpeed、Ray、vLLM:處理底層擴充與推理。
- Tinker-Cookbook 相容性:讓 OpenRL 也能接到 Tinker 風格端點。
如果把這些工具放一起看,你會發現一件事。AI 團隊真正缺的,常常不是模型能力,而是可重複的流程。Pretraining 很吸睛,但真正把產品做出來的,多半是 post-training 和 evaluation loop。
這也是為什麼 OpenRL 這類工具值得看。它不是在搶模型排行榜的新聞版面。它是在補一個很實際的工程缺口。
這對 AI 團隊現在代表什麼
先講結論。不是每個 RL 工作流都該立刻搬去 Kubernetes。那樣只會把複雜度換個地方藏起來。真正有價值的是,研究邏輯和基礎架構邏輯終於能切開。
如果你的團隊本來就跑在 Kubernetes 上,OpenRL 很值得試。尤其是你已經有共用 GPU 叢集、內部 CI/CD、以及標準化部署流程。這時候把 RL post-training 接進去,會比在 notebook 裡面硬拼乾淨很多。
如果你還在用單機 notebook 做 fine-tuning,這個專案就是提醒。工具鏈正在往共享、可重複、自架的方向走。你現在省掉的那點工程,之後通常都會用更高的維運成本補回來。
我覺得接下來幾個月,重點會在兩件事。第一,OpenRL 會不會繼續補齊更多 recipe。第二,其他團隊會不會跟進,把 post-training 變成更標準的控制平面。如果這條路走得順,Kubernetes 可能會更深地進到 AI 訓練流程裡。
對開發者來說,最實際的建議很簡單。先看你們團隊現在是不是把太多時間花在調叢集,而不是調模型。若答案是肯定的,那 OpenRL 就不是玩具。它是你該拿來做基準測試的工具。