Fixing LLM forgetting in ES fine-tuning
This paper shows LLM fine-tuning with evolution strategies can drift, and anchored weight decay can curb it.
This paper shows LLM fine-tuning with evolution strategies can drift, and anchored weight decay can curb it.
- Research org: Unspecified in arXiv abstract
- Core data: No benchmark numbers in abstract
- Breakthrough: Anchored Weight Decay constrains updates toward initial model parameters
Fine-tuning large language models is usually sold as a straightforward trade: adapt the model to a new task and hope the old skills stay intact. This paper argues that the story is messier. In the authors’ view, the “forgetting” people see during evolution-strategy-based fine-tuning is often not permanent loss at all, but performance drift that can recover later in training.
That matters for engineers because it changes how you diagnose regressions. If prior-task performance can bounce around during optimization, then a temporary dip does not necessarily mean the method is broken. It may mean the update path is wandering through a part of parameter space that is only weakly constrained.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is about a familiar problem in continual learning: after you fine-tune a model on a new task, it may get worse on earlier tasks. Recent work had suggested that evolution strategies, or ES, were especially prone to this kind of forgetting when used for LLM fine-tuning.
ES is attractive because it is simple, scalable, and inference-only during training. The issue is that if it causes models to lose prior capability, that limits its usefulness for multi-stage or continual adaptation. The authors are trying to separate a real algorithmic weakness from a misleading training dynamic.
Instead of treating forgetting as a fixed failure mode, the paper asks whether the observed drop in prior-task performance is actually reversible. That distinction matters because reversible drift can be managed, while true forgetting often requires a different training strategy altogether.
How the method works in plain English
The paper’s first move is conceptual: it reframes prior-task forgetting as performance drift rather than irreversible forgetting. In the authors’ experiments and analysis, prior-task performance often recovers during ES training, which suggests the model is not always “losing” something permanently.
The second move is diagnostic. The paper says this drift is not unique to ES. Similar behavior can also show up in reinforcement learning fine-tuning, which means the problem is broader than one optimization method.
Then the authors look at why the drift happens. Their explanation points to ES training dynamics, especially random walk behavior in weakly constrained directions of the weight space. In other words, if the optimization has room to move in directions that are not strongly anchored, the model can wander enough to hurt earlier-task performance.
To address that, they introduce Anchored Weight Decay, or AWD. The idea is simple: add parameter-space regularization that keeps optimization closer to the initial model parameters. Rather than letting the weights drift freely, AWD nudges training back toward the starting point.
That design choice is practical because it does not require changing the overall ES setup. The paper presents AWD as a stabilizer for training, not as a new model architecture or a new benchmark suite.
What the paper actually shows
The abstract does not give benchmark numbers, so there is no numeric score to quote here. What it does claim is qualitative but still useful: AWD stabilizes prior-task performance while preserving target-task performance.
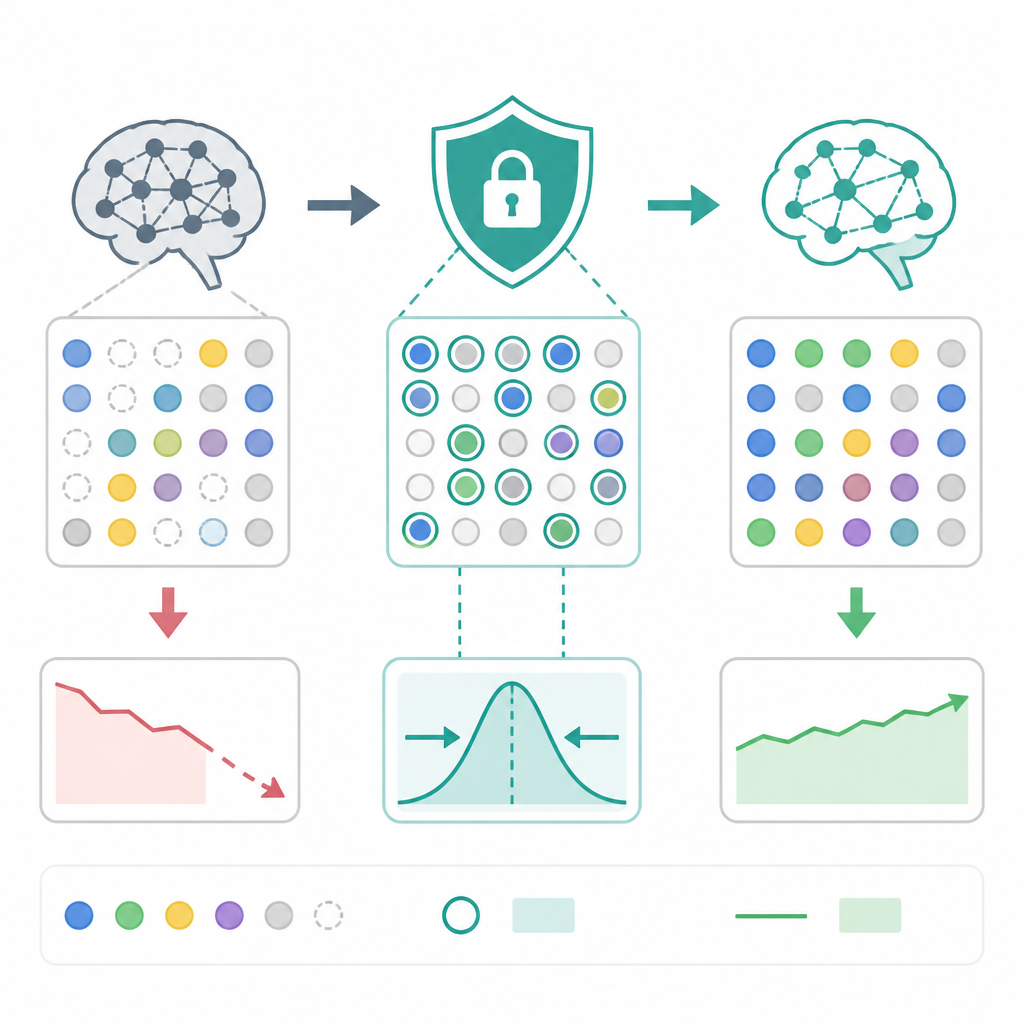
It also says AWD can deliver benefits comparable to using much larger ES population sizes, but at much lower computational cost. For developers, that is the most concrete engineering takeaway in the abstract: if a bigger population was your brute-force fix for instability, AWD may offer a cheaper way to get similar behavior.
The paper’s broader claim is that prior-task forgetting under ES is largely avoidable. That is a stronger statement than simply saying “we improved one metric,” because it reframes the problem as something you can control with regularization and training dynamics rather than accept as a built-in limitation.
Another important detail is that the authors position ES as a promising approach for continual learning in LLMs. That matters because ES has already been attractive for its simplicity and inference-only training, and this paper argues that its biggest perceived weakness may be manageable.
Why developers should care
If you are fine-tuning models in stages, especially across multiple tasks, this paper suggests you should watch for transient drift instead of assuming every dip is permanent forgetting. That can change how you evaluate checkpoints and when you stop training.
It also gives you a concrete regularization idea to try: anchor the weights toward the starting model. Even without the full paper’s implementation details, the concept is easy to understand and fits into the broader family of parameter-space regularization methods.
For teams balancing quality and compute, the “large population size versus AWD” comparison is especially relevant. If the abstract’s claim holds up in the full paper, AWD could reduce the need to spend extra compute just to keep earlier capabilities from wobbling.
Limitations and open questions
The abstract is clear about the direction of the result, but it does not provide benchmark numbers, task names, or training setup details. That means you should treat the claims as promising but not yet fully quantified from the information available here.
It also leaves open how AWD behaves across different model sizes, task types, or more realistic production fine-tuning pipelines. The abstract says the method preserves target-task performance and stabilizes prior-task performance, but it does not explain the full trade-off curve.
Finally, the paper’s explanation of drift points to weakly constrained directions in weight space, which is a useful mental model, but the practical question is how robust that diagnosis is across other fine-tuning regimes. The abstract suggests the issue is broader than ES, but it does not map out exactly where the boundary lies.
Bottom line
This paper’s main contribution is not just a new regularizer. It is a reframing of “forgetting” during LLM fine-tuning with evolution strategies as a mostly manageable training dynamic, plus a simple way to reduce it.
For engineers, that means ES may be more viable for continual adaptation than recent concerns suggested. The key idea is to keep the model anchored, avoid unnecessary drift, and judge regressions carefully before assuming the method has truly forgotten the old task.
// Related Articles