Why “edge of stability” can help generalization
A new paper links chaotic, high-learning-rate training to generalization via a “sharpness dimension” built from the Hessian spectrum.

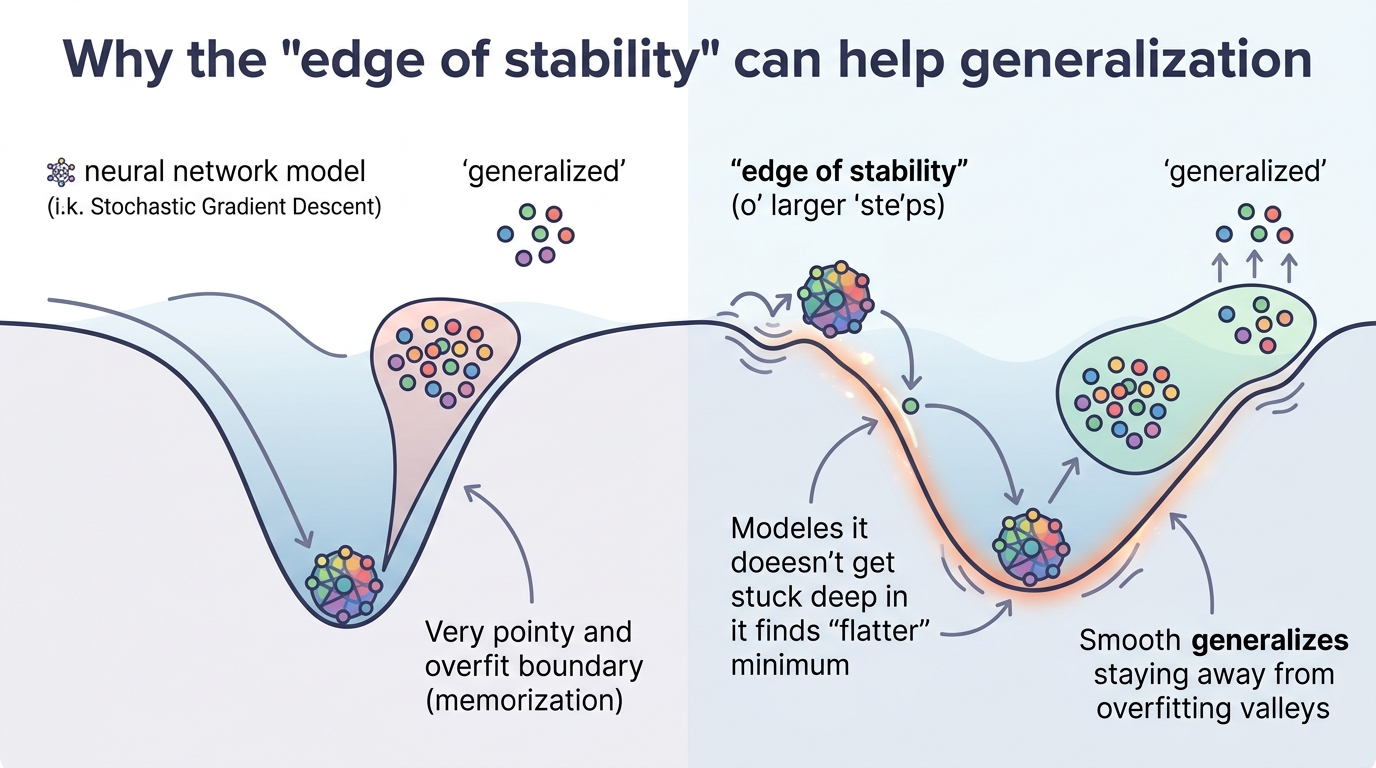
Modern neural nets are often trained with learning rates that push optimization right up to the edge of stability. That regime can look messy—oscillations, chaos, and non-convergent dynamics—but this paper argues that the mess may be part of why these models generalize well. The authors formalize that idea with a new notion of dimension and a generalization bound that depends on the full curvature structure of the loss landscape.
The paper is Generalization at the Edge of Stability. For engineers, the practical takeaway is straightforward: if you have seen large-learning-rate training behave strangely yet still produce strong test performance, this work offers a theory for why that might happen, and it suggests that the usual summaries of sharpness may be too coarse to explain it.
What problem this paper is trying to fix
There is a long-standing tension in deep learning: training dynamics are often unstable, especially with large learning rates, yet the resulting models can generalize better than more “well-behaved” runs. The abstract describes this as the edge-of-stability regime, where optimization becomes oscillatory and chaotic instead of settling neatly into a single point.

The problem is not just empirical weirdness. It is a theory gap. Prior explanations of generalization in this setting have leaned on simple curvature summaries such as the trace or spectral norm of the Hessian. Those are useful, but they compress a lot of information into a few numbers. This paper argues that such summaries miss the structure that actually matters when training dynamics are chaotic.
That matters for practitioners because training recipes are increasingly tuned by feel: learning rate schedules, batch sizes, optimizer settings, and stability tricks are often chosen to balance speed and accuracy. If the real generalization signal lives in the geometry of the chaotic regime, then understanding that geometry could help explain why some aggressive training setups work so well.
How the method works in plain English
The core move is to model stochastic optimizers as random dynamical systems. In that view, training does not necessarily converge to a single parameter vector. Instead, it can settle into an attractor set, and in the regimes the authors study, that attractor may be fractal-like rather than point-like.
From there, the paper borrows intuition from Lyapunov dimension theory and introduces a new quantity called the “sharpness dimension.” The name is a clue: this is meant to capture how the local sharpness of the landscape interacts with the dynamics of training. Rather than looking at one curvature statistic, the approach uses the complete Hessian spectrum and the structure of partial determinants.
That is an important distinction. A trace or spectral norm tells you something about overall curvature, but it can hide how curvature is distributed across directions. The paper’s claim is that this directional structure is exactly what becomes relevant when the optimizer is operating at the edge of stability. In other words, the training trajectory is not just bouncing around randomly; its long-run behavior is shaped by finer-grained geometry.
In practical terms, you can think of the method as asking: if the optimizer is effectively exploring a complicated attractor instead of converging to a point, how large is that attractor in an intrinsic sense? The sharpness dimension is the answer the authors propose, and they then connect it to a generalization bound.
What the paper actually shows
The main theoretical result is a generalization bound based on the sharpness dimension. The paper states that generalization in the chaotic regime depends on the full Hessian spectrum and the structure of its partial determinants. That is a stronger and more detailed statement than what you get from trace-based or spectral-norm-based analyses.
Importantly, the abstract does not provide benchmark numbers, error bars, or a table of exact performance gains. So there are no concrete metrics to quote here. What it does say is that experiments across various MLPs and transformers validate the theory and also shed light on grokking, the phenomenon where models suddenly transition from poor to strong generalization after extended training.
That combination—proof plus experiments—is the useful part. The theory says the edge-of-stability regime is not just a nuisance side effect of training; it may be mathematically tied to how generalization emerges. The experiments suggest this is not limited to one architecture family, since the authors report validation across both MLPs and transformers.
Still, the abstract keeps the details high level. We do not get the exact experimental setup, the datasets, the training schedules, or the size of the observed effects from the source provided here. So the safest reading is that the paper supports its claims across multiple model types, but the abstract alone does not let us assess how broad or how strong those results are in practice.
Why developers should care
If you build or tune neural networks, this paper points to a simple but useful idea: instability is not always a bug. In some training setups, especially with large learning rates, the chaotic regime may be part of the mechanism that leads to better generalization. That means “stable” training is not automatically “better” training.
It also suggests that common diagnostics may be too blunt. If you are only watching loss curves, gradient norms, or a single curvature summary, you may miss the geometry that governs generalization in these regimes. The paper’s emphasis on the full Hessian spectrum implies that the shape of curvature across many directions can matter, not just the largest eigenvalue or the average curvature.
For people working on optimizer design, scaling laws, or training analysis, that is a useful shift in perspective. It implies that future tools for understanding training may need to inspect richer spectral structure, especially when models are trained near the edge of stability.
Limits and open questions
The biggest limitation is also the most honest one: the abstract gives a high-level theory, but not enough implementation detail to know how expensive the proposed analysis is, how it scales to very large models, or how easy it would be to use in day-to-day training workflows.
There is also a conceptual gap between theory and practice. A bound based on the sharpness dimension may explain generalization, but it does not automatically tell an engineer how to choose a learning rate, when to expect grokking, or how to instrument a training run in real time. The paper points toward those questions without fully answering them in the abstract.
Even so, the direction is clear. If the authors are right, then the edge-of-stability regime is not a strange corner case. It is a meaningful part of the optimization landscape, and one that may hold clues to why modern neural networks generalize as well as they do.
- The paper models stochastic optimizers as random dynamical systems.
- It introduces a new “sharpness dimension” inspired by Lyapunov dimension theory.
- It proves a generalization bound tied to that dimension.
- It argues that the full Hessian spectrum matters more than trace or spectral norm alone.
- It reports experiments on MLPs and transformers and connects the theory to grokking.
For developers, the main lesson is not “always use huge learning rates.” It is more nuanced: the relationship between instability and generalization may be structural, not accidental. That makes the edge of stability worth studying, not just avoiding.
Related Articles

Safe Continual RL for Changing Real-World Systems
Apr 22

Random Neural Nets Show Phase-Shifted Fluctuations
Apr 22

Bounded Ratio RL Reframes PPO's Clipped Objective
Apr 21

Sessa puts attention inside state-space memory
Apr 21

MathNet Benchmarks Math Reasoning and Retrieval
Apr 21

Prompt Engineering Is Becoming Infrastructure
Apr 21