讓影片模型學會讀時間
這篇 arXiv 論文把「速度」變成影片模型要學的能力:可偵測快慢變化、估計播放速度,還能做速度可控生成與時間超解析。

影片模型過去多半只看「畫面裡是什麼」。這篇 Seeing Fast and Slow: Learning the Flow of Time in Videos 想補上另一半:模型也要懂「發生得多快」。作者把時間視為可學習的視覺概念,讓模型能辨識速度變化、估計播放速度,還能在不同時間尺度下生成或修復影片。
這件事看起來像播放控制的小細節,但其實不是。對影片理解來說,快轉、慢動作、低幀率、時間壓縮,會直接改變可見線索與動作模式。模型如果只會認物體和動作,卻看不懂時間被怎麼拉伸或壓縮,就很容易誤判事件。
這篇論文的切入點很清楚:時間不該只是影片資料的背景設定,而應該是模型要學會操作的維度。這也是它跟一般影片辨識工作的差別。它不是只問「這是什麼影片」,而是問「這段影片是怎麼流動的」。
它想解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
作者先指出一個現實落差:影片一直是電腦視覺的重要題目,但研究社群對「時間流逝」這件事的感知與控制,著墨其實不多。很多系統訓練時都把幀率、播放速度、時間解析度當成預設條件,彷彿這些因素永遠不會變。

但真實世界不是這樣。影片可能被快轉、慢放、壓縮,或是來自不同的拍攝節奏。當模型預期的時間尺度和實際輸入不一致時,它就可能看錯動作,漏掉細節,甚至把同一段事件解讀成完全不同的東西。
所以這篇論文把問題拆成兩層。第一層是感知:模型能不能看出影片有沒有被加速或減速?第二層是生成:模型能不能在指定速度下產生影片,或把低幀率、模糊的影片補成更細的時間序列?作者認為,要回答這兩件事,模型就得直接從影片裡學時間,而不是把速度當成外掛資訊。
這個方向對開發者很重要,因為它把「時間」從資料前處理問題,提升成模型能力的一部分。換句話說,未來影片模型不一定只要懂內容,還要懂節奏。
方法怎麼運作
這篇工作最核心的想法,是利用影片本身自然存在的結構來做自監督學習。也就是說,不靠大量人工標註速度,而是從影片裡的運動與時間關係,讓模型自己學出速度感知能力。
作者利用多模態線索與時間模式,訓練模型辨識播放速度是否改變,並估計一段影片的速度。這兩個能力是後續更進階任務的基礎。先學會看懂快慢,才有機會進一步控制快慢。
接著,這些時間推理能力被拿去做資料整理。論文提到,這個方法幫助作者從雜訊很多、來自真實世界的來源中,整理出一個目前最大規模的慢動作影片資料集。重點不在於資料一開始就很乾淨,而在於模型能夠從混雜素材裡篩出可用的慢動作片段。
有了這批資料之後,作者再往兩個方向延伸:一個是速度條件式影片生成,也就是讓模型依照指定播放速度產生動作;另一個是時間超解析,將低 FPS、模糊的影片轉成更高 FPS、時間細節更豐富的序列。這兩者本質上都是對時間的控制,不只是對畫面的銳化。
論文實際證明了什麼
先講清楚一點:這份摘要沒有公開完整 benchmark 細節,也沒有提供數字、分數或完整 ablation 結果。所以如果你想直接比較它和既有方法誰高誰低,從摘要本身看不到。
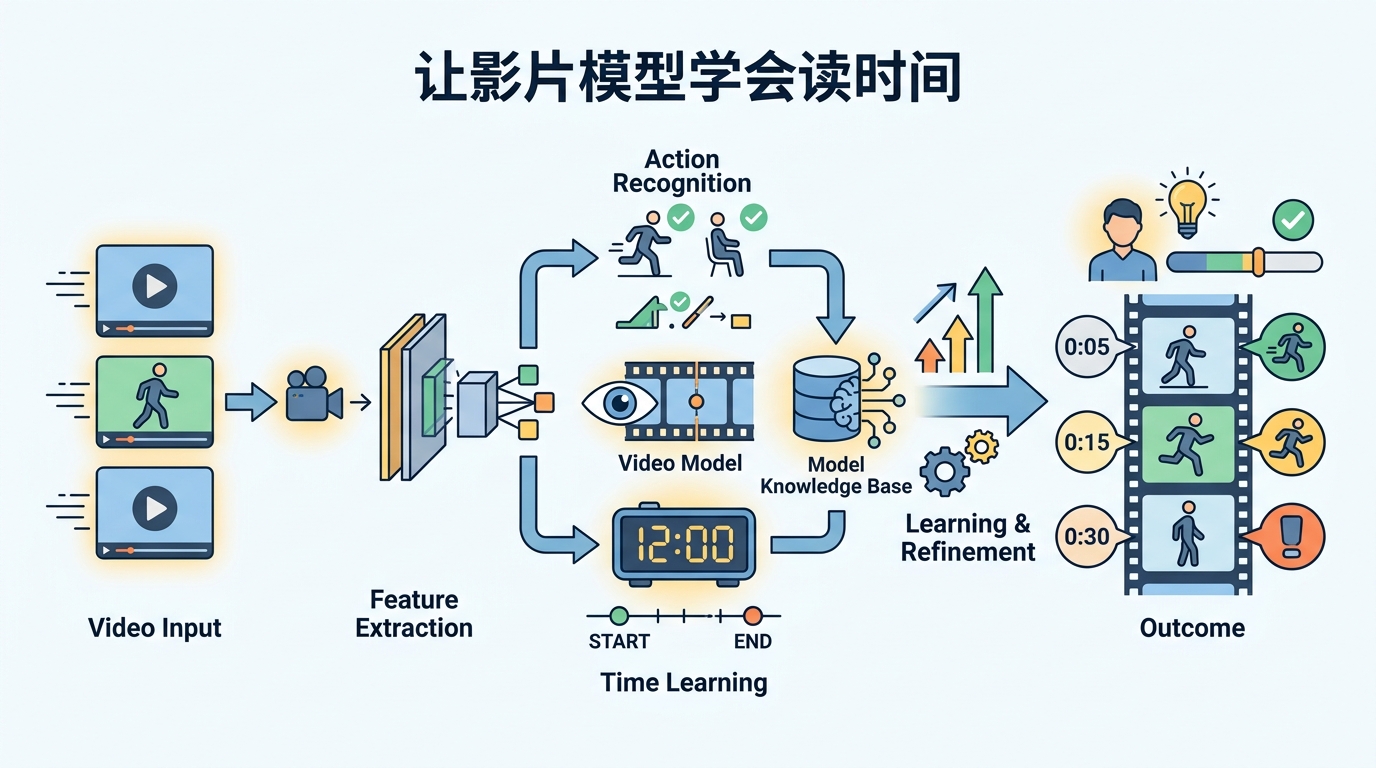
但摘要還是透露出一條完整的技術路線:先用無標註或弱結構的影片學出時間推理,再用這個能力去整理慢動作資料集,最後訓練出能做速度感知生成與重建的模型。這代表作者不是只做單點任務,而是在建立一套「時間可學、可估、可控」的流程。
這件事的意義在於,它把時間當成可操弄的維度,而不是固定不變的輸入條件。影片模型過去常被要求辨識物體、動作、場景,這篇論文則更進一步,要求模型表示並控制事件如何隨時間展開。
摘要也提到幾個更大的應用方向,包括 temporally controllable video generation、temporal forensics detection,以及更豐富的 world models。這些都還偏向研究願景,但至少說明作者認為「理解時間」不只是生成影片的附加功能,而是能延伸到鑑識與世界模型的核心能力。
對開發者有什麼影響
如果你在做影片 AI,這篇論文最值得注意的地方,是它把時間解析度提升成第一級控制項。很多團隊會先想解析度、風格、提示詞控制,卻忽略播放速度本身也會改變模型行為。這篇工作提醒我們:時間不是背景參數,而是模型輸出品質的一部分。
實務上,這可能影響幾種常見工作流。第一類是影片生成系統。當你希望模型產生的動作有特定節奏,速度控制就會很重要。第二類是影片增強管線。若輸入是低 FPS 或模糊素材,時間超解析可能比單純做空間銳化更有價值。第三類是鑑識或審核工具。若影片可能被快轉或慢放,模型就需要先看懂時間是否被動過手腳。
第四類是資料集建置。作者提到可以從真實世界雜訊來源整理慢動作影片,這代表未來資料工程不一定只能依賴人工逐幀標註。只要時間推理能力夠強,模型本身也能幫忙做篩選與整理。
影片生成:讓輸出符合指定播放速度與動作節奏。
影片修復:把低幀率、模糊影片補成更細的時間序列。
內容鑑識:偵測影片是否被加速或減速。
資料整理:從雜訊真實影片中挖出可用的慢動作素材。
從工程角度看,這篇論文提供的是一個方向:把 temporal reasoning 當成可訓練能力,而不是前處理假設。這會讓影片模型更有彈性,也更能適應不同來源、不同幀率、不同時間尺度的資料。
限制與還沒回答的問題
這篇摘要的最大限制,就是資訊還不夠完整。它沒有公開 benchmark 數字,所以目前無法判斷實際提升幅度,也不能知道它在不同任務上的相對表現。
另一個沒說清楚的地方,是魯棒性。摘要沒有交代模型在高壓縮、嚴重運動模糊、非典型鏡頭運動下,速度判斷會不會失準。這些都是真實部署時很常遇到的狀況。
還有一個關鍵問題是泛化。論文提到自監督學習,也提到從 noisy in-the-wild sources 建資料,但摘要沒有說明模型跨資料域、跨拍攝裝置、跨影片風格時表現如何。這會直接影響它能不能從研究環境走到實際產品。
另外,作者強調能從雜訊來源整理大規模慢動作資料集,這雖然很有吸引力,但也意味著資料品質可能不均。只要來源夠雜,後續速度控制的穩定性就會很依賴篩選流程。也就是說,方法很有前景,但真正能走多遠,還要看它在髒資料上的表現。
為什麼這題值得繼續看
整體來說,這篇論文在做的事情很明確:讓影片模型不只知道「畫面裡有什麼」,還知道「這些畫面怎麼隨時間流動」。這是影片理解的一個重要擴張。
對研究來說,它把時間從隱含條件變成明確學習目標。對開發來說,它暗示未來的影片工具可能不只會修圖、補幀、生成內容,還要能管理節奏、速度和事件展開方式。
如果你正在做影片生成、影片增強、內容鑑識,或任何需要處理時間尺度的系統,這篇工作都值得放進觀察名單。它不是在告訴你一個已經做完的產品,而是在提醒你:下一代影片模型,可能真的要先學會讀時間。
簡單講,這篇論文把問題從「影片裡是什麼」推進到「影片是怎麼跑的」。這個轉向不只對學術有意義,對實作也很直接,因為很多影片 AI 的錯誤,根本不是看錯內容,而是看錯速度。